
Expel recently had the privilege of participating in Infosec Jupyterthon. It was an awesome opportunity to share what we’re learning about this open-source technology as well as learning from others about what they’re finding, and unique perspectives on how to up our game in efficiency when it comes to incorporating this technology into infosec processes.
Following our presentation, which you can check out here, a few participants reached out to me to ask about our process for developing and maintaining an entire library of threat hunting notebooks. In the spirit of sharing with the open-source community, I wanted to write a detailed response that’s available to everyone.
We believe that hunting is content that can and should be developed by subject matter experts (SMEs), and our best SMEs for hunt development are our SOC analysts. The job of engineering is to set up systems to enable those SMEs to focus on the parts of the problem that are relevant – like enabling really simple code deployment by linking GitHub and our CI/CD pipeline with JupyterHub (we wrote about that here).
Another example is using a shared chassis for all of our notebooks, allowing for sharing and reuse of boiler-plate components like API access, analyst notes and report formatting (we also wrote about that here). By focusing efforts on these things as enabling technologies, our analysts can focus on building hunting techniques and analytics rather than worrying about barriers to deployment.
Building off my last blog post, I thought I’d cover how we use configuration files to build and configure our hunting notebooks, which allows our analysts to build new hunting notebooks without requiring them to learn Python.
Going on the hunt
So how do we do it?
I’m going to share a “Hello world!” type example to demonstrate our implementation of this framework. But you can check out the complete source code here.
Our goal behind the source code is to make it easy for our analysts to generate notebooks based on a standard template, yet allow each of the notebooks enough flexibility to provide unique capabilities required for a specific technique.
For example, some of our hunts are based on network artifacts while other hunts are based on process artifacts or cloud platform API usage. Hunts based on network artifacts may have specific capabilities related to reverse DNS, IP address attribution or host to source traffic patterns. However, a process artifact hunt may require different capabilities such as hash reputation lookups and parent/child process relationship patterns.
We need to keep the development simple and ensure that all our notebooks have the common capabilities yet allow the flexibility for our analysts to configure the specific capabilities they need to analyze and report on their hunting data sets.
In order to do that, we’re going to use yaml files to store easily modifiable configurations, and then build the notebooks from those configurations using the nbformat package in Python following five steps (plus one optional step).
Step 1: Configure Docker
I started off by configuring a working directory. In my example, I used a Docker container as my engine to run my build. I like using Docker because I can preconfigure my dependencies and anyone with Docker can later run my same build without having to configure any of their own dependencies.
To get started with Docker, create a Dockerfile or use the example from my source code. Otherwise, make sure you have Python v.3.5+ installed as well as nbformat and PyYAML.
Step 2: Create Configuration Directory
Next, I created a directory to store my YAML configuration files. In my source code example, I used the “hunt_configs” directory. I have two example hunts in this directory right now (see below); however, you can have as many configuration files as you’d like. Each configuration file builds a new hunting notebook.
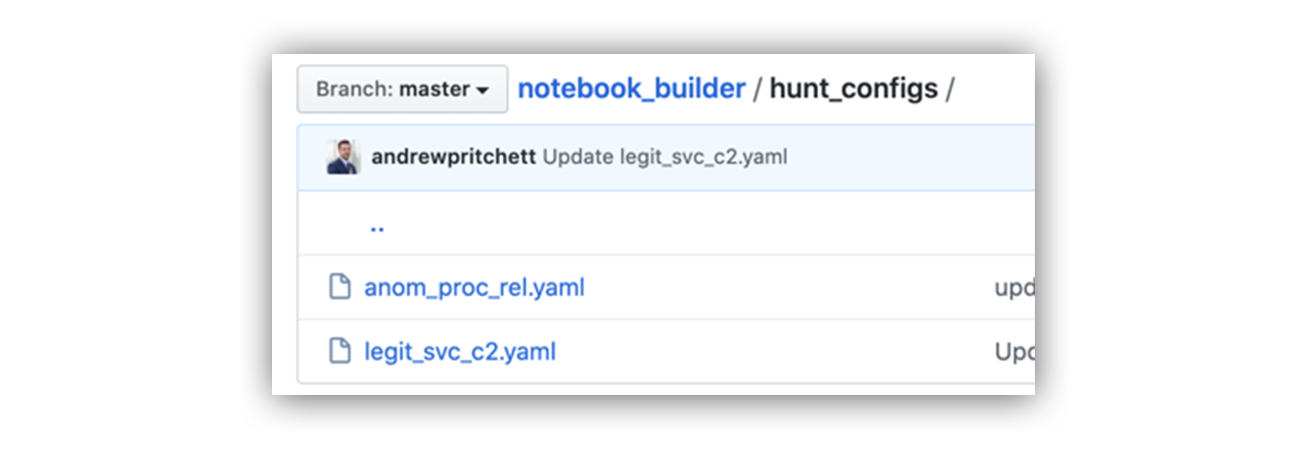
Configuration file directory
Step 3: Create YAML Configuration Files
I then created a few YAML configuration files and created some key value pairs that I need in order to give my notebooks their unique characteristics and tools. Each configuration file builds a new hunting notebook.
Once you create the file, it’ll look something like this:
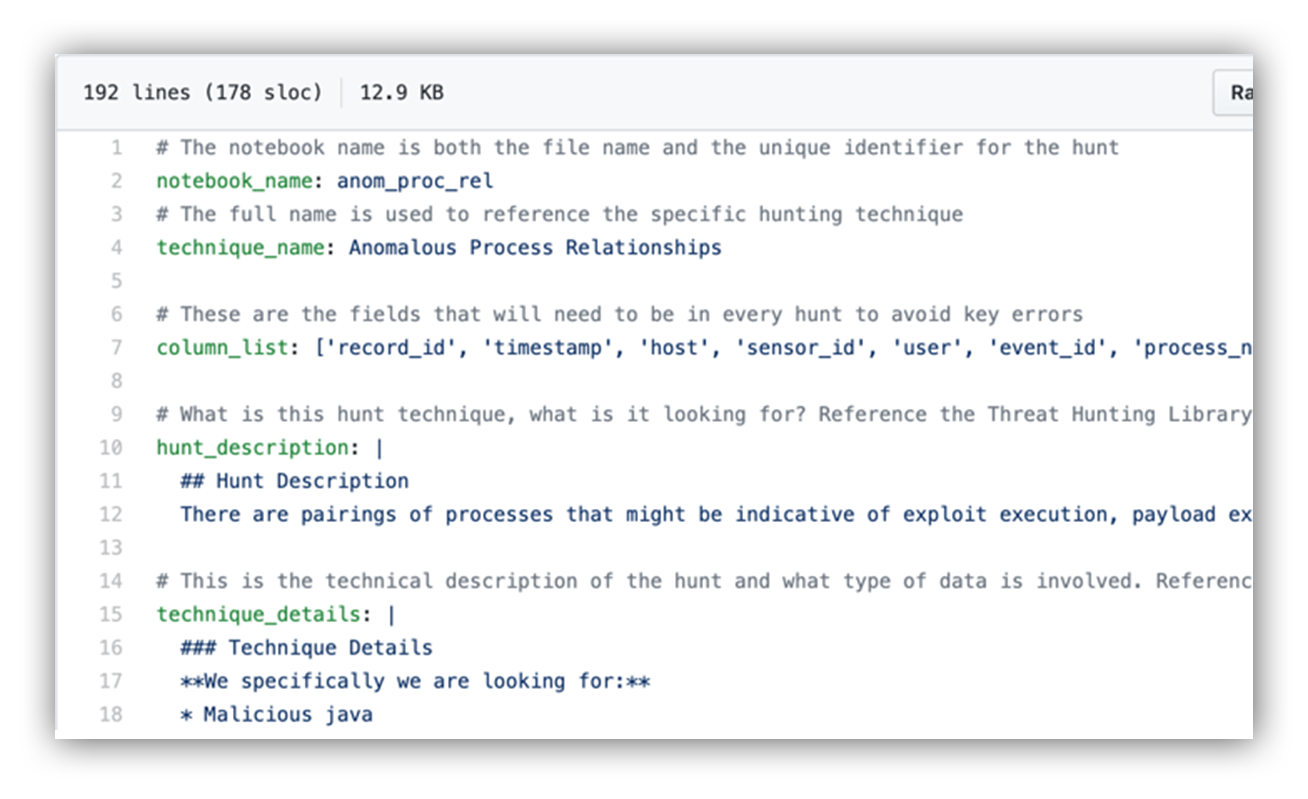
YAML configuration file data
Repeat step three as many times as you need to make sure you have enough notebooks for your hunting technique library.
Step 4: Adjust the Build Script for Your Use
Time for the Python builder script. I named my script “notebook_builder.py.” You can name your script anything you want, just make sure that if you’re using Docker, you update the filename in the Docker configuration files. This builder script is what reads the configuration files and generates our Jupyter notebook files (*.ipynb files).
The primary function in this script is “run_builder().” First, this function needs to be able to find the current working directory and the directory which contains all of your YAML configuration files:

Code to locate configuration files
Second, the function will iterate over each of our configuration files so we ensure that we make a unique build for each configuration file. See an example below.

Code to iterate over configuration files
The function will then give our new notebook object a variable name. This is also where we can add any global metadata and create a new list to store all of the cells we’re about to build. In the example below, I’m using notebook metadata to hide the code cell input from view. I generally like to hide the code cell input so the user experience in Jupyter is more like a web application rather than a Python script.
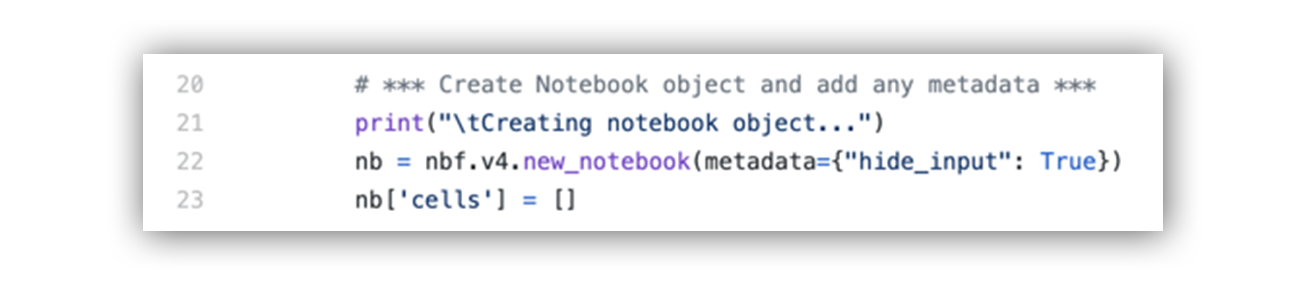
Code to build notebook object
From here forward, we repeat the process of building and appending cells to our notebook cells list. There are many options for building your notebooks, including the ability to append “new_code_cell” or “new_markdown_cell.” Any data you want to be evaluated by your Jupyter notebook needs to be written in as string data.
In this example, I want to import the Pandas package into my notebook. To do this, I’ll append a “new_code_cell” with the string value “import pandas.” If I want to print “Hello world!” I’ll append a “new_code_cell” with the string value “print(‘Hello World!’).”
Nbformat provides helpful docs for more advanced use cases.

Writing code into a notebook cell
To insert data into our notebook, all we need to do is reference the data from our YAML file and insert the data using either the f-string or format string methods, like this:

f-string example

Format string example
Our example hunting notebooks all have a title, a data normalization function, a “Start Hunt” button, a decision support section and a hunt data visualizer. The bottom section of the notebook is where each notebook takes on its unique characteristics. In the bottom section, we’ve assembled a set of capabilities to assist with the analysis of the specific hunting techniques. These capabilities live in the “downselects.py” module. At Expel, we call these capabilities downselects.
Downselects are designed to help our analysts break down the larger hunting technique theory into smaller sub-theories or subsets of information. We believe this helps to break down the “find a needle in the haystack” approach to hunting. We also use downselects to provide analysts specific tools they will need to triage their hunting results.
Downselects can be enrichment lookups like VirusTotal or Greynoise, or graphs and charts to visually display data in different aspects, or timelines and tables that focus on a specific sub-theory. When the analyst discovers interesting events or patterns in the downselects, they are armed with pivot points to triage and scope the larger dataset, rather than tearing through the dataset aimlessly. To learn more about how we use downselects, checkout our Jupyterthon presentation here.
In order to access our downselects and build them into our notebooks, our builder script needs to iterate through a list of our downselects:
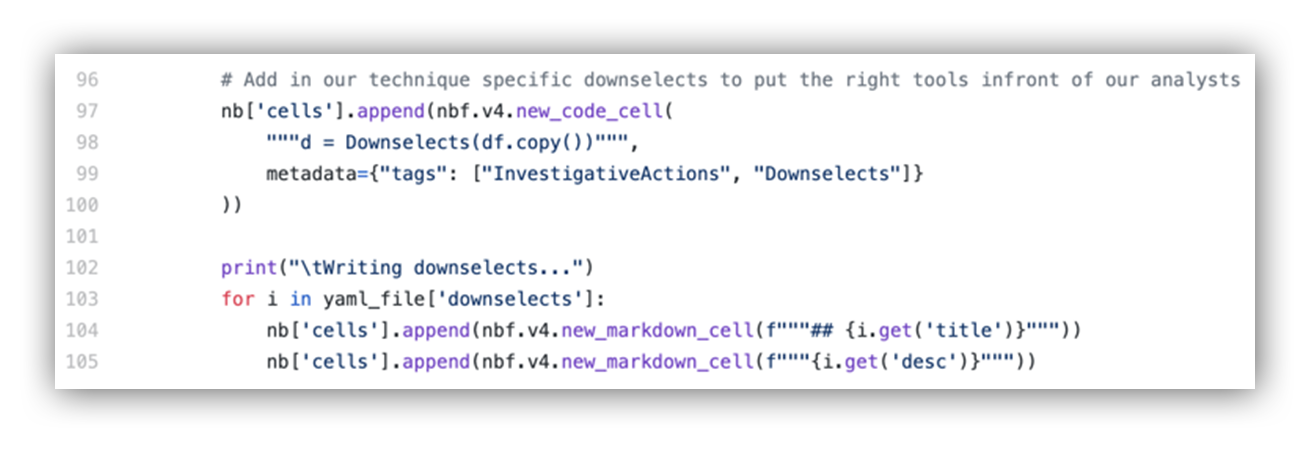
Code example to iterate through list of dictionary objects
We can then insert the function name and parameters from “downselects.py” as a string into a new_code_cell:

Image: code example to execute function specified in YAML config file
Lastly, our script needs to write our notebook object to a unique file name; otherwise, it will keep writing over the same filename as it iterates over our configuration files.
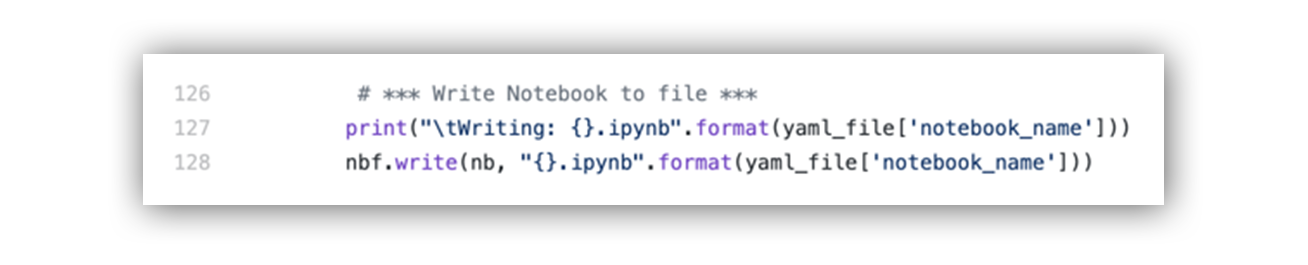
Code example to write notebook
So now we have the instructions written in order to build our new hunting notebooks. Let’s build and run them in Jupyter!
Step 5: Build and Run Our Hunting Notebooks
So now we have the instructions written in order to build our new hunting notebooks. Let’s build and run them in Jupyter! The Docker instructions are designed to build the hunting notebooks when you run the Jupyter notebook service, using this command: “docker-compose run ‐‐service-ports notebook.”
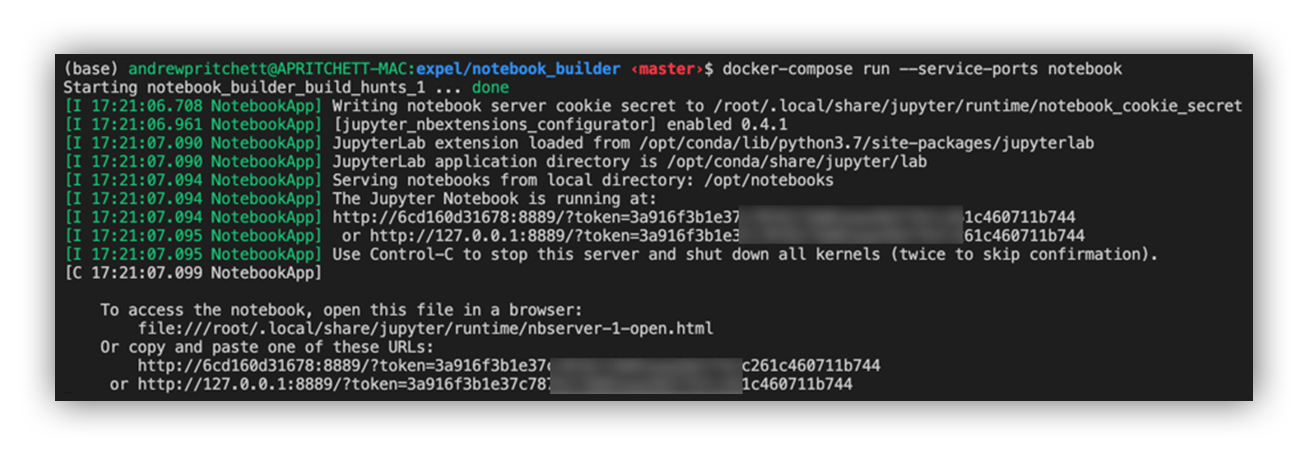
Command line example of build process
When we use the Jupyter notebook link, we can see our newly created notebook files in our file tree.
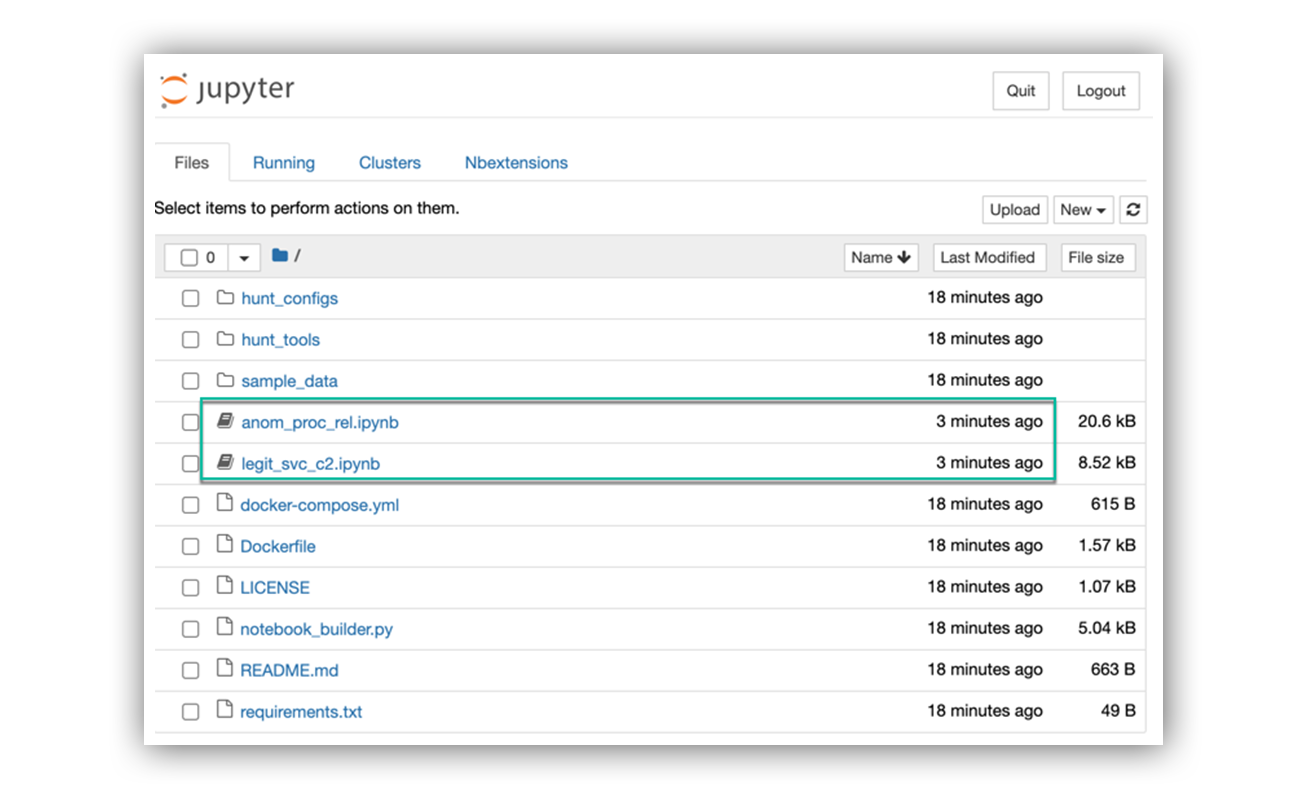
Jupyter notebook server and new hunting notebooks
Select one of the “*.ipynb” files to view the hunting technique notebook in Jupyter.

Example of running built notebook
If you need to make a change to one specific notebook or hunting technique, all you need to do is update the specific configuration file for the technique and re-run the notebook service to rebuild the notebooks.
If you need to make a change to your core code base, you can modify your “notebook_builder.py” build script and re-run the notebook service. This way you can ensure that your notebooks will be rebuilt the same way and will run on the latest version of the build.
Optional last step (a bonus!): Add to Deployment Pipeline
If your organization has a pipeline for continuous integration, such as using CircleCI, your organization can configure the build to run following your change review process. This ensures that your end users are always working off of the latest deployment of your notebooks.
Final thoughts
Whether you’re using notebooks for customer analytics, performance analytics, data science, threat hunting, sales projections or machine learning, Jupyter notebooks can be really helpful for sharing, presenting and collaborating on data.
We hope this post helps take some of the time and stress out of managing your notebooks and allows you more time to actually engage with your data.
Huge shout out to everyone who helped put Infosec Jupyterthon 2020 together and to the attendees who gave me the inspiration to write this post. The event was a blast, and we hope to see you all again soon!
Have more questions? Let us know!



