
Wearing the engineering cap in a cloud-native environment means living in a world that revolves around open-source tech.
There’s a dizzyingly vast ecosystem of powerful open source tools at our disposal, sure – but very few of them offer the ability to solve more abstract organizational challenges by themselves. When it comes to open-source tools, sometimes it’s like playing a game of Tetris … you have to figure out how to use and shift those tools to wind up with a winning development approach.
Mastering open source Tetris is great, but what’s even more important when it comes to developing anything is to truly understand the needs of your users. And if you can figure out not just what they need but how to provide them with a platform they can use to solve their own problems … that’s when things start to get really exciting.
In this post, I’ll talk about why we at Expel realized it was time to reevaluate how users interact with our core engineering platform, our approach to building a system that makes our users happy (with the help of Terraform and Atlantis) and walk you through a hypothetical scenario of what our new system looks like from the user’s perspective.
If you or your team are beginning to think about how to build a more robust Terraform execution pipeline, or you already have one and are looking at how to transform it into something more self-serviceable and palatable for end-users, then read on – this post might be for you!
Core engineering platform vision
At Expel, engineering is divided into feature teams. These feature teams own one or more services in their entirety. This includes developing the features, managing the CI/CD pipelines, managing the monitoring and owning the on-call rotation for their services.
A site reliability engineer’s (SRE) role is to provide a platform that makes doing all of this easy. In fact, the core platform should make it so easy for a feature team to self-service provisioning their own cloud infrastructure that it would be less convenient to ask someone to do it for them.
Platform plight
A critical step to building any feature, let alone an entire platform, is incorporating user feedback into the development process.
Towards the beginning of development, our users let us know that the process for managing GCP CloudSQL instances felt tedious and obtuse. They were right – it was.
While teams were given the keys to control their own destiny, they were not equipped with much tooling to help them get there. They were forced to internalize the Terraform DSL well enough to write their own code, manage their own statefiles, rationalize IAM policy and spend time grokking the nuances of each provider’s implementation. This can feel like a lot of yak shaving when you’re just looking for a darn database!
And furthermore, we were seeing missed opportunities to apply SRE best-practices, patterns and guard rails to new infrastructure. For example, at Expel, SREs have developed a standard pattern for a Postgres CloudSQL slow query configuration that we think is usually a great idea to have enabled. But with our setup at the time, engineers did not have an easy way to inherit these benefits. Having users miss out on out-of-the-box database optimizations such as this would be no good!
Any of this sound familiar?
It was clear we needed some form of abstraction that would reduce the burden of Terraform development as well as package up SRE best practices into the code being written. We sat down to rethink our approach.
Enter Atlantis and Expel modules
What we knew we needed
Okay, so we knew we needed to provide an easy way for engineers to manage their own cloud resources and monitors that would come with SRE’s cloud expertise out of the box. So what exactly were our requirements?
- Consumable abstraction for users: This is the tricky one! The platform needs to be easy to use. We need some form of central abstraction so that, as a platform user, I can set up everything I need without being forced to internalize how it all works under the hood.
- Infrastructure-as-code: This should probably go without saying, but all infrastructure changes must be managed via Git. While the benefits of the Infrastructure-as-Code philosophy are outside the scope of this post (though here’s a great overview by Hashicorp), it’s worth calling out as a requirement.
- Completely automated: It’s critical that automation drives all changes. Making infrastructure changes by executing code from an engineering workstation is widely discouraged for a number of reasons, including an increased attack surface, inconsistent code execution environments and lack of scalability.
- Auditability: We must be able to easily tie every infrastructure change to an individual user.
What we chose
After pulling our requirements together, this is the stack we chose to solve our problem:
- Terraform: We embrace Hashicorp’s Terraform for defining our entire Google Cloud and Datadog footprints.
- Atlantis: An open source Terraform workflow tool for teams. Atlantis enables teams to manage Terraform changes in an easy and familiar way.
- Expel Terraform modules: An internal collection of opinionated libraries supported by SRE that packages the most common infrastructure and monitoring needs into parameterized Terraform modules. Users love them because they can hit the ground running without requiring a deep understanding of low-level cloud intricacies. SRE loves them because we can enable self-service for our users while still ensuring our expertise carries over everywhere that changes are happening – even (and especially) when we’re not aware of them.
- GitHub: Where it all comes together. The Terraform code change management is not just tracked in GitHub, but the code execution itself is orchestrated through GitHub comments from the associated pull request (PR).
Advantages and takeaways
There are a host of advantages that the system provides our org. Here’s what we love about it:
- Enables self-service for most common infrastructure needs. There’s no “DevOps” team waiting for you to throw a ticket over the wall to have your GCS bucket and service account provisioned. The process is only gated by how fast you can review and comment!
- No sacrifice is made to SRE best practices in exchange for the self-service model. Externalizing all of SRE’s common patterns and experience into documented, easy-to-use modules ensures that SRE expertise is packaged in with service owners’ deployments.
- Atlantis solves a common Terraform gotcha around scenarios involving multiple concurrent Terraform changes by implementing its own distributed locking mechanism. Atlantis will prevent any other proposed changes from being processed by applying its own special lock to any Terraform configuration that has an open PR against it. This allows users to work out of a branch and apply their change before it’s merged to master, which protects users from having to submit multiple PRs to solve `terraform apply` failures. In order to tee up another change, an engineer must either apply and merge the pull request, close it or manually release the lock via a special UI provided by Atlantis.
- Crazy visibility. While Git should be the source of truth for all changes regardless of how Terraform code is applied, having all orchestration happening out in the open in the PR fosters a healthy and transparent environment.
- By using the GitOps approach and ensuring only machines are executing our Terraform code, we reduce our attack surface by limiting the number of credentials and privileged hosts.
Putting it all together
As you can probably imagine, we’re always looking for new ways to enable our analysts and keep our customers safe. And since Expel’s backend is built using a microservice architecture, new applications get spun up all the time.
Now we’re going to walk through a hypothetical end-to-end example to demonstrate how the process works as a platform user.
In this scenario, we’ll pretend for a moment that we’re software engineers spinning up a brand new service named `super-slick-service` that will benefit from using the open source software Redis. You can almost hear the (albeit contrived) conversation from the design meeting conference room:
Jim: Hey! If our new app needs Redis, I heard GCP offers a managed Redis service called Memorystore. How can we go about sprinkling some of that on our app?
Ali: I think SRE provides a Terraform module that we can use to provision that.
Jim: Cool, but how can our app access the instance? Do we need to ask someone to set up DNS records for it? And how can we get some viz into instance health for things such as system capacity?
Ali: The module sets up everything we need, including the DNS and Datadog monitors that will alert our team if we’re beginning to run into capacity issues. Just run through the doc – it should only take a few minutes.
Pull up the core platform docs
Okay, we know what we need to do. Now it’s time to stress the importance of platform documentation! Effective tools won’t do nearly as good if it’s not clear how to harness their power. Check out this README for our Memorystore Terraform module:
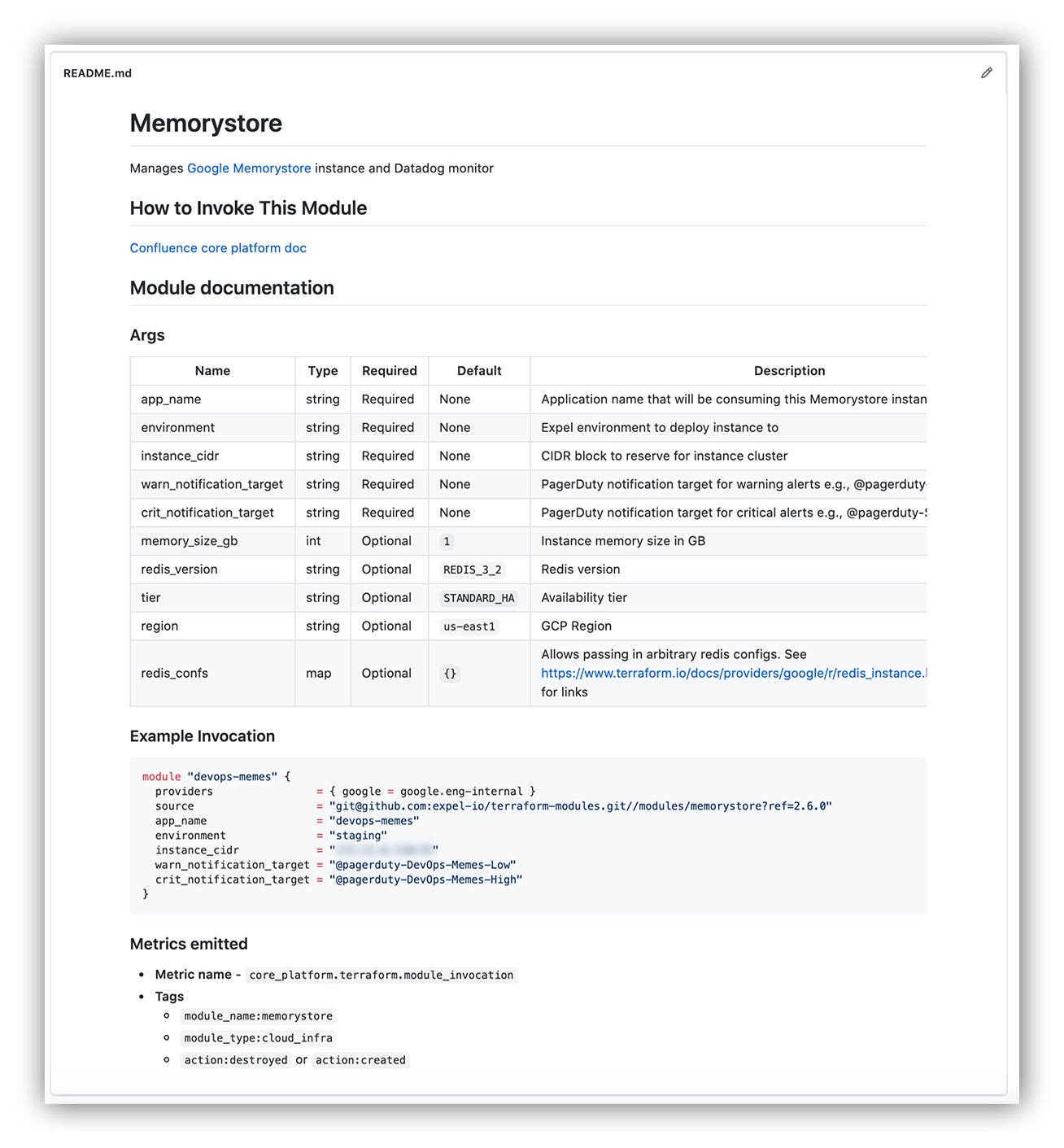
Core platform Terraform module documentation
Call the module with your desired parameters
Okay, so now we’ve pulled up the documentation and are going to invoke the Memorystore module and pass in just the basic bits that we need to specify.
We’re throwing the following code into our favorite IDE:
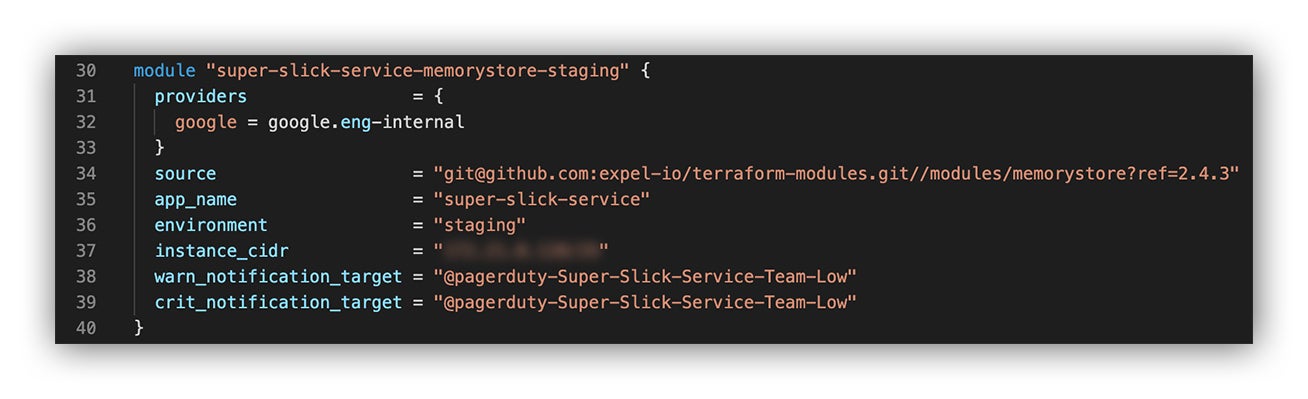
Calling the Terraform Memorystore module
Apply your change in GitHub via Atlantis
Cool. So now we have our code and we’re submitting it via pull request in GitHub. Here’s where the magic happens.
Submitting the pull request
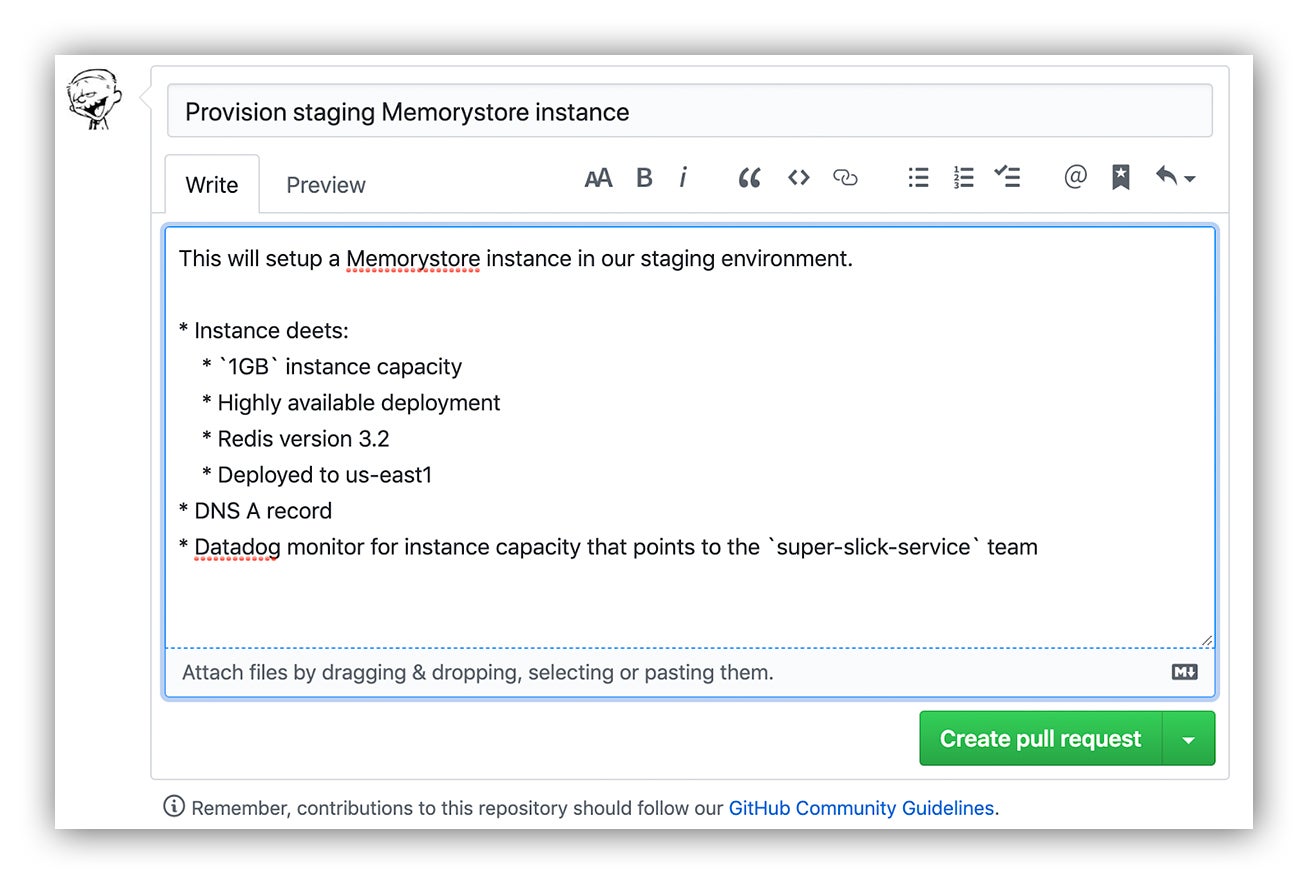
A GitHub pull request submission to call our Terraform module
Reviewing the plan output
One of the most important steps in any Terraform workflow relies on the `terraform plan` feature. The `terraform plan` provides the user a snapshot of what Terraform would do in the event that it had been executed. It displays the delta between the desired state of your infrastructure as defined by your current commit versus its actual state provided by the providers’ API. This is a critical step in any Terraform workflow because while Terraform enables you to orchestrate impressive feats of progress, it in turn enables you to orchestrate impressive feats of destruction if you don’t exercise great scrutiny upon your plan review.
Luckily, this part is Atlantis’ bread and butter. Atlantis provides a wonderfully executed mechanism to sidestep the need for platform users to set up a local Terraform toolchain: GitHub comments! It does this by leveraging webhooks to allow GitHub users to execute Terraform via comments in the GitHub pull request. As long as you’re authorized to operate on your application repo, you’re able to harness the power of Terraform while dodging a whole category of headache that can come in the form of cumbersome state file management, mismatching Terraform and provider versions or brittle Terraform execution pipeline builds. It’s a beautiful thing!
Once your PR is submitted, Atlantis will manage the `terraform plan` on your behalf and submit the output for review in comment-form. Not only does this allow the author to review the proposed changes with minimal fuss, but it cranks up the visibility for the entire team to eleven since the plan output is dropped right in the PR!
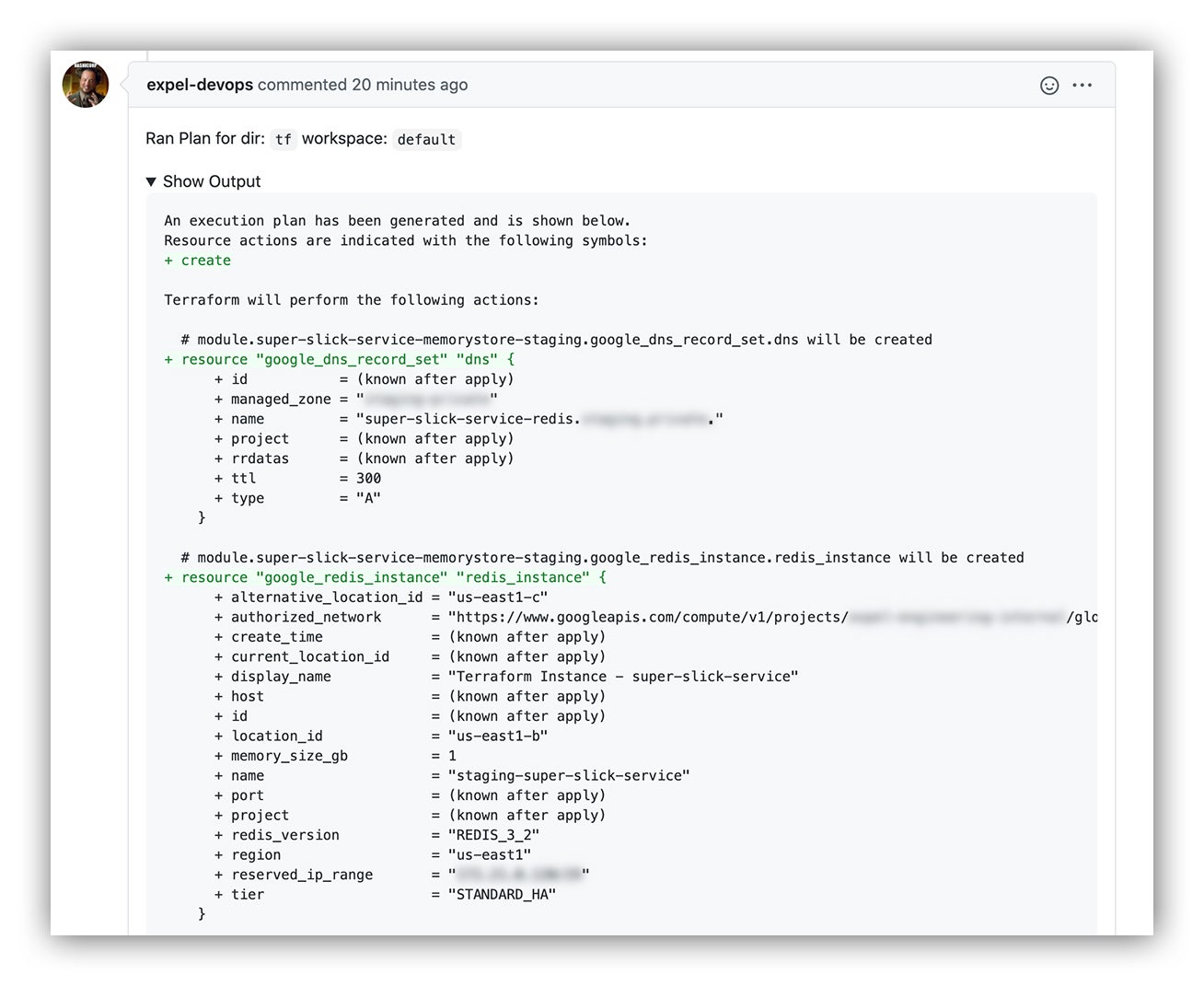
Terraform plan output as commented on our GitHub pull request via Atlantis
Executing the change
Great. Your code and `terraform plan` changes have been reviewed by team members and have been approved. Now how to put your change into effect? Just drop a comment in GitHub with an `atlantis apply` to pull the trigger on your change!
And when the `atlantis apply` step is finally complete, you can count on a neat summary dropped in as – you guessed it – another GitHub comment! Sweet, now we can merge!
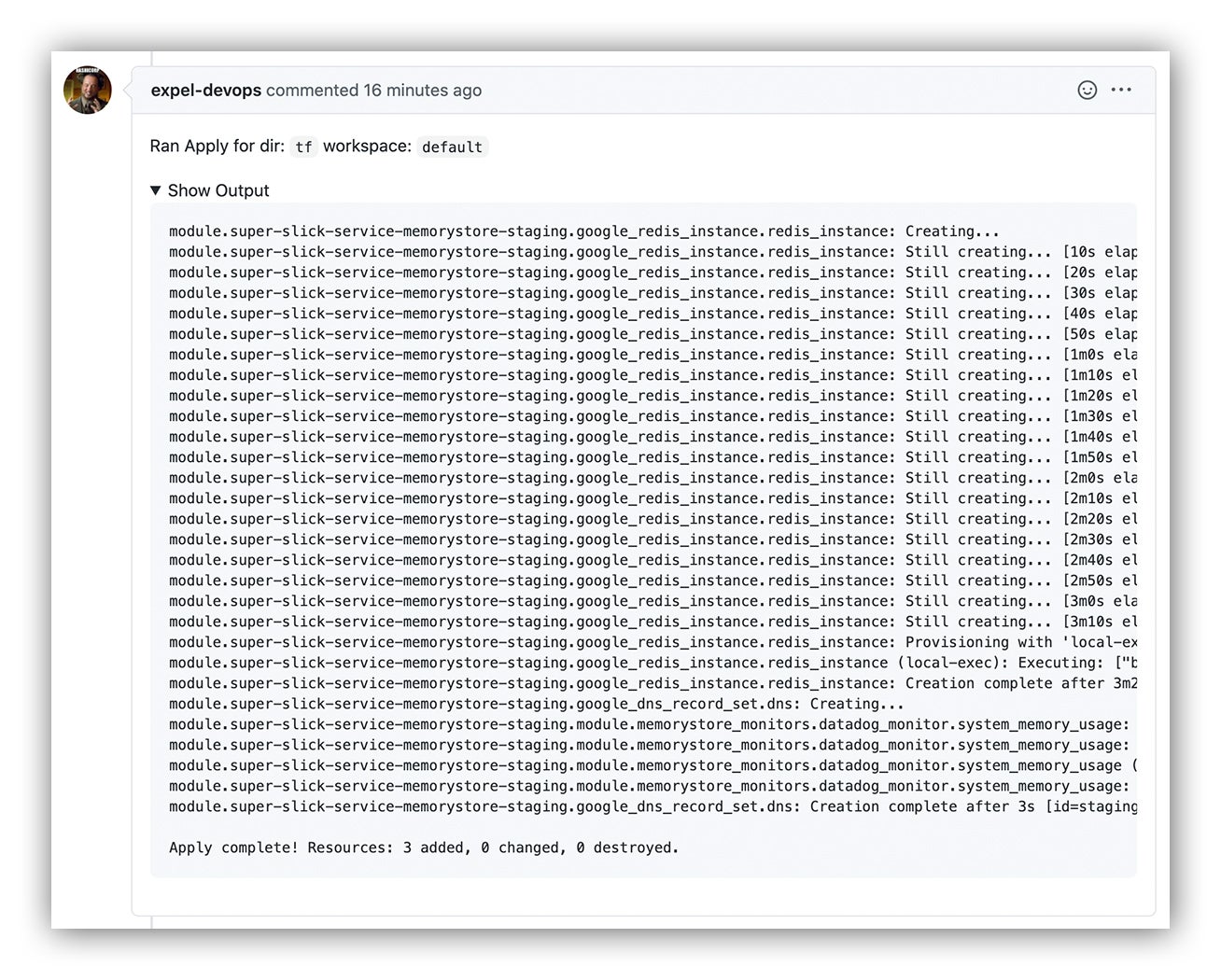
Terraform apply output as commented on our GitHub pull request via Atlantis
You can now see all the effects of your pull request being applied.
Memorystore instance
We have a brand new Memorystore instance, hot off the press:
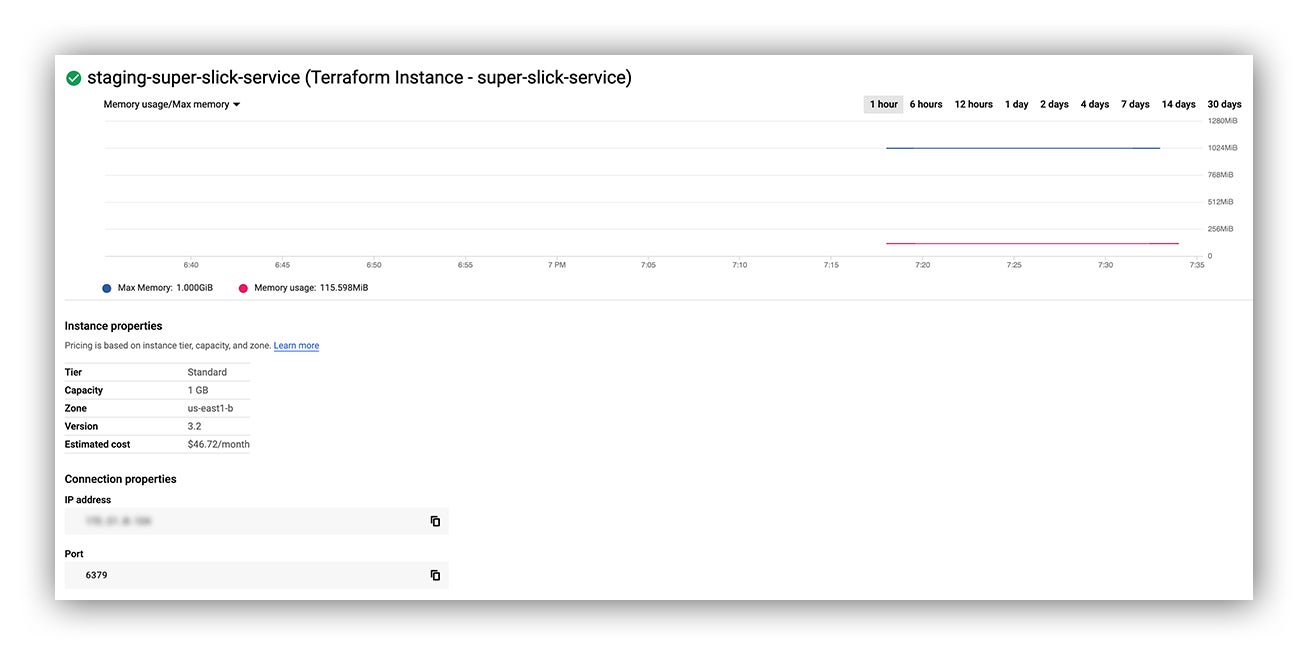
GCP Cloud Console reflecting our new Memorystore instance
DNS record set
A DNS A record has been provisioned for the instance:
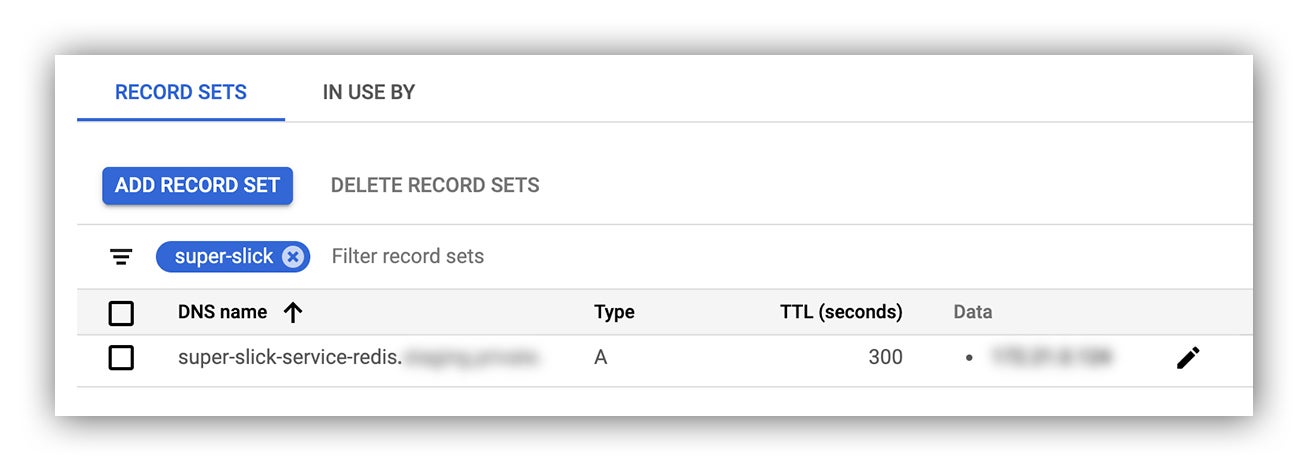
GCP Cloud Console reflecting our new DNS record
Datadog monitor
You can see here how our Datadog monitor query has been automatically scoped to our new instance ID:
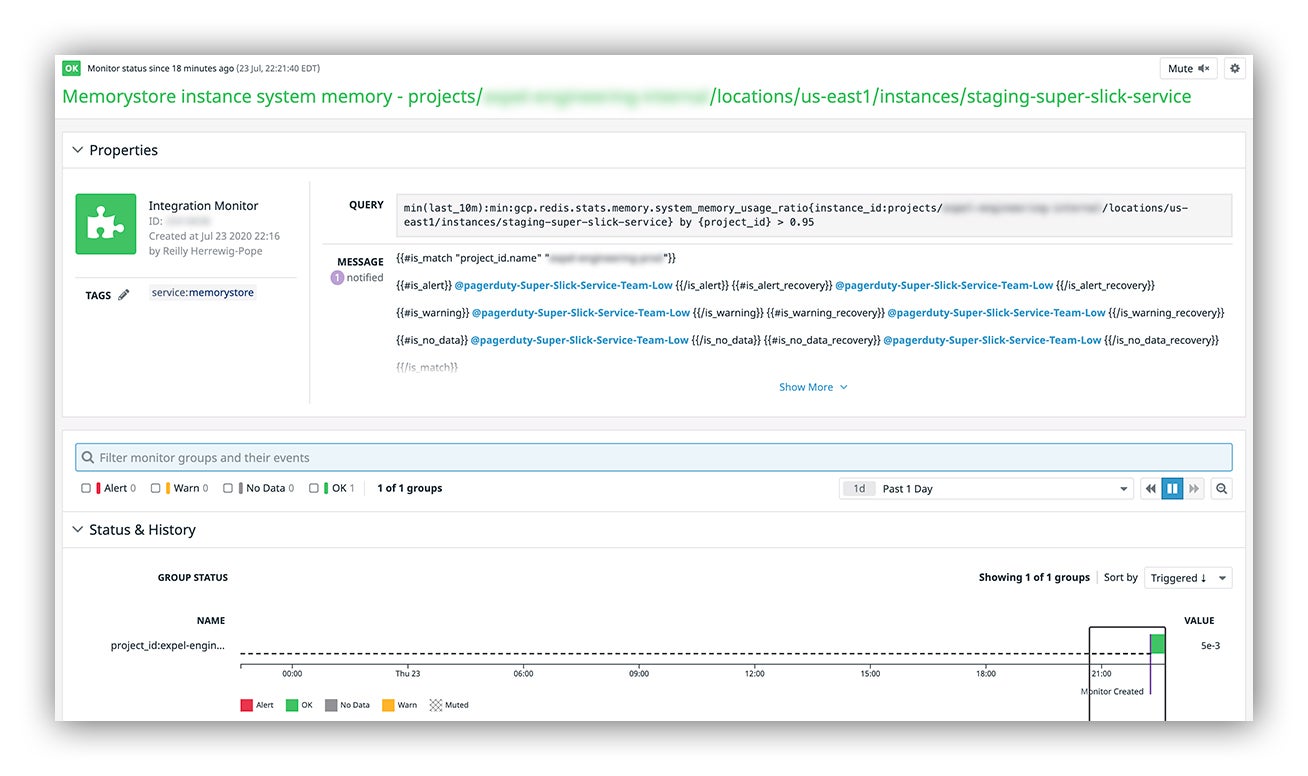
Datadog web console reflecting our new capacity monitor
Measuring platform use
Another important aspect to platform engineering is measuring user engagement. We want the platform to emit usage metrics wherever possible to help SREs understand how and when the platform is being used. In this case, we bake some telemetry into our modules by using local-exec provisioners that run from the Atlantis pod when modules are being invoked. Having this in place lets us look back in time to make more informed, data-driven decisions.
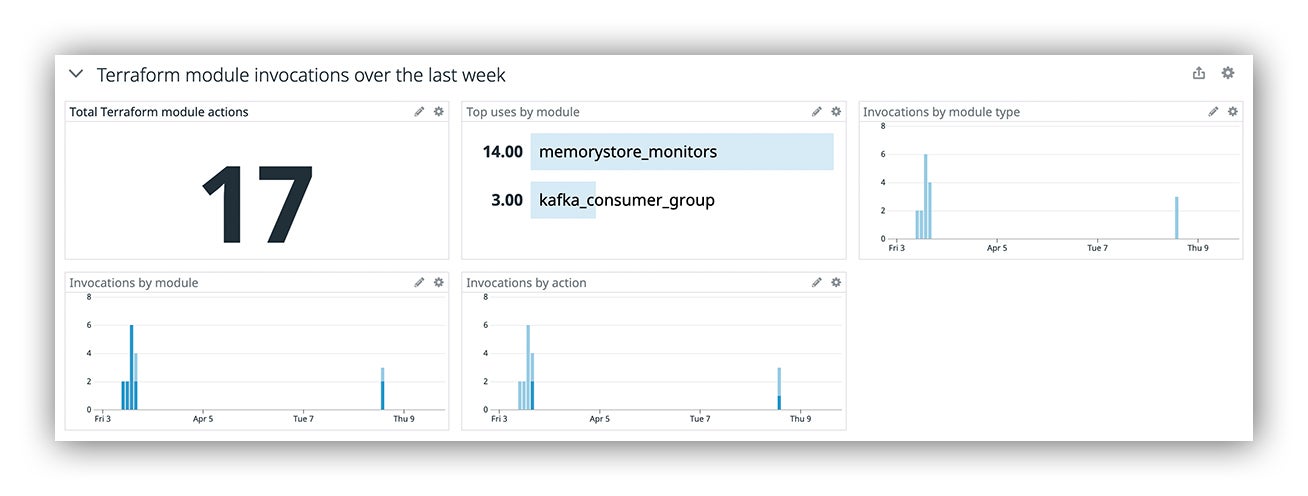
Datadog web console reflecting module invocations over the past week
Parting thoughts
Delivering a useful platform can be challenging. If we’re steadfast in our commitment to remain engaged with our users as well as continuing to view technologies not as one-size-fits-all solutions, but as discrete tools meant to be assembled to create a powerful experience, we set ourselves up to build a successful platform that our users look forward to using.
Want to find out more? Luke Jolly has kindly given back to the Atlantis community via the Atlantis contribution. You can see the conversation here.
If you have any further questions, feel free to reach out to us!
: Hey CISOs, stop guessing when it comes to cloud security")
: What attackers don’t want you to know")
: The cloud security mythbuster—what MDR really means for cloud")
: Making a roadmap for cloud security")