
Our auto-close marketing emails (AME) feature frees up time for our analysts and was developed using machine learning. Here’s how we did it.
Those of us in cybersecurity must understand and respond to rapidly changing threats and vulnerabilities, but it’s challenging because there’s traditionally a trade-off between analyzing a lot of data and analyzing data quickly. Specifically, phishing analysts may become desensitized to the sheer volume of benign alerts over time.
This underlines the importance of using benign indicators to identify and remove low-risk emails to allow security operations center (SOC) analysts to focus on the really important stuff: potentially malicious emails. We turned to machine learning (ML) to boost SOC effectiveness and reduce alert fatigue. Here’s how we did it.
Expel’s auto-close marketing email model
Our objective was straightforward: increase the time our analysts have available for triaging malicious emails by decreasing the time wasted on false positives. We do this by removing some of the benign email activity from the alert queue and providing decision support to assist with triage.
No shade to our marketing colleagues, but we decided to target marketing emails in this motion first, because:
- They’re easy for humans to identify, which means it’s easier to teach a machine to find them.
- They’re considered benign by definition.
- They represent a big chunk of the low-signal alerts that SOC analysts have to triage. An estimated 30%(!) of our phishing queue is considered marketing outreach.
Based on these learnings, we had what we needed to build our auto-close marketing emails (AME) feature. AME is designed to:
- Automatically remove the email from the queue if there’s ≥95% probability it’s a marketing email.
- Highlight for analysts if the email has marketing-like characteristics (probability between 85% and 95%).
- Highlight for analysts if the email can’t be classified as a marketing email and *spoiler* may contain suspicious indicators (<5% probability).
AME helps us focus our efforts on the worst-of-the-worst emails in our alert queue by removing false positives and filtering data into a usable signal. ML won’t automate all our problems away, but it can support us in our day-to-day workloads, leaving more mental energy for detecting and remediating true positives.
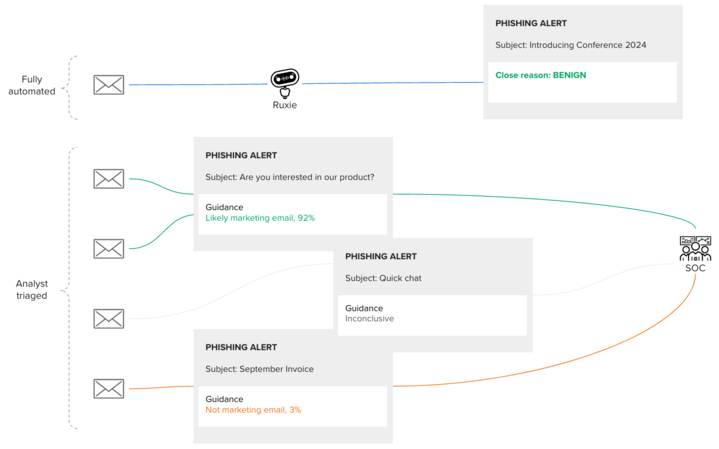
So what kind of magic did we use to make this happen?
At first, we didn’t have quality training data because, as you can imagine, SOC analysts are busy identifying threats and remediating active attacks on our customers. We decided not to ask analysts to also label alerts “marketing / not marketing” during fast-paced active triage time to prevent even more strain.
How did we build the model, then?
With very little labeled data, we couldn’t rely strictly on supervised learning techniques (e.g., Random Forest and XGBoost) to build AME. Instead, we used an ML technique called semi-supervised learning that uses business heuristics to feed into an ML model. This model both helps with incremental labeling and learns “marketing / not marketing” patterns from the programmatically labeled data.
Cool, right? (We’ll talk more about implementing semi-supervised learning in AME in part two of this series—stay tuned.)
Within AME, we identified a number of features that allow us to hone in on a few key patterns, a few of which are listed below.
- Marketing characteristics
- Is the email coming from a marketing department?
- How many images are included within the email?
- Does the phrasing and tone sound similar to other known marketing emails?
- Malicious characteristics
- Does this email have characteristics that our analysts have flagged before in previous malicious emails?
- How old is this sender domain?
- Was this sender associated with previous malicious activity?
Guardrails
Great. We have a model that looks pretty good. High-five, and push to production, right?
Not so fast. Let’s take a step back and review the overall system. While AME does a comparable job identifying “marketing/not marketing” emails, the overall goal is to identify “benign/malicious” emails. Using guardrails, we make sure that AME aligns to that objective.
This means we:
- Assess each email for known suspicious indicators.
- Send the email to an analyst if it has a high creep score, regardless of what AME says.
By evaluating these things regardless of the model’s predicted outcome of “marketing/not marketing,” we’re better able to prevent malicious emails from falling through the cracks.
For example, if I get an email from <thisismarketing@itsmepaypal.com> and this sender domain was just created last week, we’ll push that email to an analyst—the young sender domain is suspicious and is an indicator that it’s a phishing attempt.
Follow along in this blog series to learn about some of the other ways we protect our customers when ML automates parts of the workflow. We’ll focus specifically on implementing SOC-centered quality control and measuring leading indicators of model degradation.
Results
We said the model was good, right? How good? What’s the aCcuRaCy?
A major struggle for data scientists can be translating their metrics from academic definitions (precision, recall, and accuracy) into tangible business metrics. This is how we’ve made our data science results meaningful.
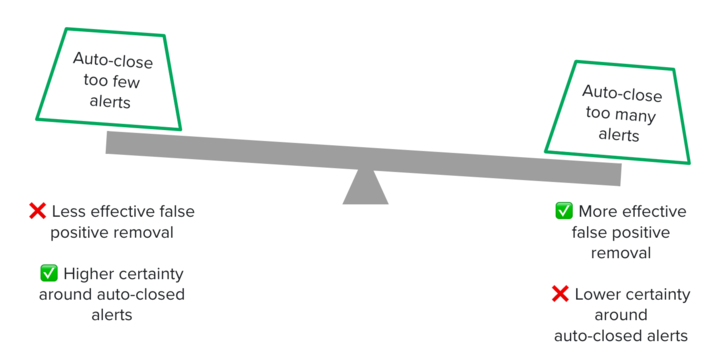
During this process, we completed a premortem to assess the worst potential outcome of this project—auto-closing something as marketing when it is in fact a malicious email. This suggested we should prioritize higher certainty around alerts removed from the queue over larger efficiency gains. By balancing these trade-offs, we demonstrated boundaries for how our model should behave and can clearly trace our model performance to business objectives. See the table below for how we broke those down.
| Metric | Business definition | Why |
| Precision | Out of the number of alerts predicted marketing (≥95% probability), how many are actually marketing? | We auto-close alerts with ≥95% probability, so it’s important to understand how many alerts AME might incorrectly auto-close and tag as “marketing.” We aim for high precision. |
| Percent of predicted marketing alerts that are benign | Out of the number of alerts predicted marketing (≥95% probability), how many were closed as benign by an analyst? | In addition to precision, we absolutely want to monitor if we auto-close anything malicious. We aim for high percent benign. |
| Percent of queue reduced by the model | When we auto-close the alerts predicted marketing (≥95% probability), how much less work do analysts have to do now? | Our overall project goal was to refocus our SOC on the most important alerts. By reducing the queue, our SOC can be more effective at finding true evil. |
Getting it to an analyst
Nice. Our model hits our business goals. How did we get this in the hands of our analysts?
After model experimentation and development, we used a shadow deployment strategy that allowed us to see how AME performs without taking action on the results. This confirmed that our model performs well on live production data and meets the expectations shown by development results.
We then opted to use a canary deployment to slowly release AME across our customer base and monitor for issues with integration. We limited our risk using this phased approach and could quickly roll back the model if results dipped below a performance threshold.
Putting it all together
We designed this application to free up time for our analysts to devote to more pressing tasks. It also provides insight into how we can best use ML techniques in application development.
- While supervised learning wasn’t appropriate for this project, semi-supervised learning proved very effective at making sense of our unlabeled data.
- Consider how your model can be used in the overall system. Does it complete a task end-to-end or does it help people make decisions (human-in-the-loop or HITL)?
- While data scientists talk at length about precision, recall, and area under the curve (AUC) in an academic setting, make sure to redefine these terms in context of your business.
- You may have built an excellent model in development, but what about checking these inferences in production and providing guardrails as needed?
This is the first entry in our AME series. Stay tuned for more…



