![Placeholder image for Why don’t you integrate with [foo]?](https://expel.com/wp-content/uploads/2021/2021/01/thumbnail-500x300-Why-dont-you-integrate-with-foo.png "thumbnail-500x300-Why-dont-you-integrate-with-foo")
 When you’re looking for a managed security provider that purports to “work with the tech you already have,” you might be dismayed to hear that there’s something you have we don’t integrate with.
When you’re looking for a managed security provider that purports to “work with the tech you already have,” you might be dismayed to hear that there’s something you have we don’t integrate with.
How can that be? Is it just not something we’ve built yet?
Well, why not?
I’ll tell you.
By the end of this post you’ll understand why our thoughts on integration are likely different from what you’ve heard elsewhere, and what this means for you if you want to work with Expel.
Building a model to prioritize needles, not haystacks
We’ve all heard the phrase, “It’s like looking for a needle in a haystack.”
Based on our many years spent working in the security industry, we’ve discovered that collecting piles of hay (AKA security signals) and hoping there’s a needle or two in there isn’t the most efficient way for us to protect anyone’s data and infrastructure.
That’s when we also realized that more integrations doesn’t mean better results.
In fact, it often results in lots of noise and a bundle of false positives.
However, there’s still a general mindset in our industry that the best move is to put all the data in one spot and then begin doing all the things.
A pile of data = amazing results?
Not always.
So why does everyone still love “haystacks” of data?
To understand this, let’s rewind the clock about 20 years and see where we’ve come from as an industry.
When it comes to answering challenging questions and getting value out of data, we’ve historically followed the business plan popularized (or documented?) by the Underpants Gnomes of Southpark.
It goes like this:
- Collect Underpants
- ?
- Profit!
Sound familiar?
Everybody loves the idea of gathering a pile of data and expecting amazing results somehow later on.
Applying the lens of the Gartner hype cycle to new technologies like data warehousing, business intelligence and big data analytics … you’ll notice an uncanny parallel to this very same business model.
A different approach: Asking questions first
At Expel, we believe in taking a different approach when you’re looking to get value out of data.
It goes something like this:
- Identify the questions to which you’ll want answers.
- Identify the speed at which you’ll want these questions answered.
- Identify the data from which you’ll derive the answers.
- Organize the data to support these use cases.
- Profit!
- Go back to step 1 and revisit periodically.
Unfortunately, this approach is twice as long as the last one.
On the other hand, it works.
Let’s take a look at it in the context of security operations.
How do we come up with questions?
TL;DR: We’re trying to find out if there’s something “bad” happening in the environment we’re monitoring. This requires us to first ask ourselves a few questions.
At Expel, we’ve come up with a standard set of initial follow-up questions that inform what we do if we do spot something bad.
But how do we know if something’s bad?
Well, our best bet is to have a lot of relevant context.
For example, what technology generated the alert? Was the alert generated from an assumed role in AWS, if so – who assumed it? Has this user done this before? Did that user assume other roles at about the same time? What’s the historical use profile of that source user? The list goes on.
Some of this context we can collect up front because it comes along with the alert.
Other context may require follow-up queries against other systems or historical records on what is “normal” in the environment.
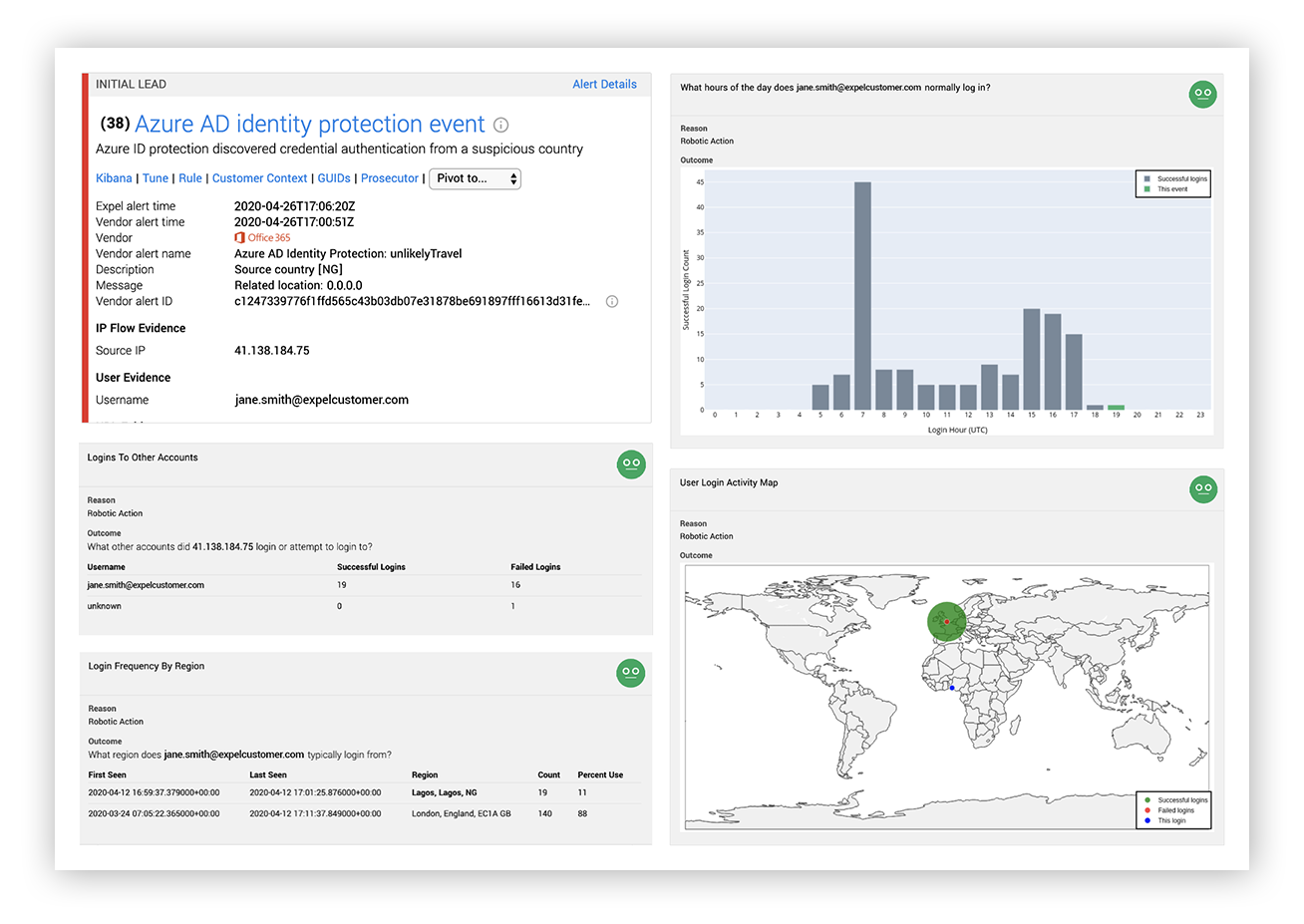
Expel alert for suspicious login post-optimization with authentication history and frequency
Why does speed matter?
Because we triage a lot of alerts with a combination of technology and smart analysts.
And chasing down the same kind of supporting information repeatedly is exhausting (and therefore, better to automate).
When you’re looking at alerts, the better the context you have the faster you can determine if what you’re looking at is for sure bad, definitely a false positive or inconclusive.
If an alert isn’t definitely bad or definitely good, it needs follow up.
We need to take time to investigate.
Time is still of the essence here so we don’t want to drag our feet, but we do this work substantially less often than we do triage work overall so we can afford to look around at potentially interesting data a bit.
Another factor to consider is when we’re doing investigations, the questions we ask aren’t going to be quite as cookie-cutter. They can vary widely based on the alert and its surrounding initial context.
Bottom line:
- We’re going to do a lot of triage, and we’re going to do it quickly.
- We need a lot of context to help streamline (and potentially automate major portions of) this process.
- Inconclusive results are less frequent, the questions are hard to predict and will vary based on the situation.
Getting answers using the old model
Let’s take a look at what happens when we use the underpants business model for security operations.
- We collect logs from everywhere and put them in one giant pile.
- We write some rules that try to make sense of this and create a huge volume of alerts.
- These alerts have limited context so we have mostly inconclusive results.
- We’re not sure what to automate, so we throw people at the problem.
I like to call this the “let’s build haystacks so we can search for needles in them” approach.
We’re firmly in the category of “biased dirty vendor” here, so take this next statement with the appropriate grain of salt. Many of the security operations approaches we see in place today resemble this old model.
When you see MDRs where SIEM is the foundation or there’s co-managed SIEM offerings, you’re probably looking at this model in action.
We don’t feel like this model works, so we approach things a bit differently.
Applying the Expel model to security data
Our approach is borne from both experience and several years of data that tells us the vast majority of incidents’ initial leads come from specific vendor technologies that generate high quality alerts.
First, we collect only alerts (not logs) that come from overall high quality sources, i.e. hay that looks like needles in the first place. Yes, Andrew, we know there’s an exception when it comes to our cloud integrations.
Our alerts probably come with decent context already depending on what tech generated them. An EDR tool is a great example of a context-rich alert data source.
Next, based on the alert and initial context, there’s other context we can grab from different systems.
Let’s automate those pivots and data grabs. For some alerts, it may be possible to grab additional automated context without pivoting on much data.
For example, what else happened on this system within +/- 5 minutes? What other systems communicated with this IP address? We now have rich context that enables our security analysts (or robots) to make good decisions relatively quickly.
As we watch this play out, if we keep close track of what analysts do next, we’ll continue to learn how we can automate the process.
Now we’re left with a much smaller volume of investigations and much more time in our day. We don’t need to answer the next set of questions with quite as much speed, because (1) the frequency of this work is way lower than for alerts and (2) we’re going to have to apply more human judgement.
What does this mean for integrations?
The primary advantage of a tech integration with a system that can collect context and orchestrate actions is speed and automation.
When questions are predictable and the repeatability of getting answers means that speed provides a huge time advantage… that’s when integrations make the most sense.
The disadvantages of integrations are twofold: you have to build them, and you have to maintain them.That’s time you could otherwise be spending making your analysts more effective.
So to figure out what we should prioritize from an integration perspective, let’s look at how we can get answers to questions in the timeframe in which we need them.
We think about four integration levels to support different degrees of predictability and urgency. Note that the amount of work required increases by level.
Levels of integration
Level 1: Accessible
When predictability of question and urgency are lower, it’s important that we can get the data, but we don’t need an integration. This fits well into the kinds of data we use during an investigation versus during initial triage.
A great example of this is a feature we call “pivot to console.”
There are security technologies in play in some of our customer environments that either don’t have APIs that allow us to gather additional context or historically have not generated signal that would have resulted in the identification of an incident. But they might support understanding what happened during one.
For these technologies, our analysts can pivot to that tech’s console directly through the Expel Workbench, and access the data there. Tracking this activity also helps us prioritize what tech we might want to integrate.
Level 2: Indirect, via SIEM
Most of the data in most SIEMs we’ve worked with has been useful when paired with high-quality security signal.
But the events, and many times the alerts produced by SIEMs themselves, are rarely the initial lead for an incident.
We’ll want to pull this data in through our Expel Assembler and correlate, via automation, relevant context into our overall alert stream. An example of this might be authentication failures that indicate brute-forcing.
Level 3: Direct, uni-directional
When we’re looking at a data source that provides reasonably good security signal, or there are effective ways to filter the incoming data so that only the high-quality signal gets through, we’ll want to integrate directly. Speed in this case is important both in finding a useful initial lead and perhaps in providing context.
An example here might be some perimeter NGFW or IPS/IDS solutions that have good APIs and alerts with decent context.
Level 4: Direct, bi-directional
Technologies we’d integrate in a bi-directional fashion not only provide high-quality security signal – the product on the other end can be modified to behave differently on the fly based on information we’re seeing.
It also likely has its own query ability where we can ask a set of predefined questions and get answers quickly (we like to say the quality of your investigation is rooted in the questions you ask).
These technologies are essential to high-quality triage and tend to get used quite a bit during investigations. EDR technologies fit well into this category.
What does this mean for me?
If you’re looking to work with Expel, this model should help explain how we think about prioritizing integrations and which integrations provide the most value in the context of security operations.
We spend most of our time on the investigative leads that have the highest likelihood to be an actual incident.
Which means they’ll require action – fast.
The more time we spend chasing our tails on alerts (or events) that don’t matter, the more time we waste and the higher the risk we’ll miss the important stuff.
And what’s “important” is contingent on each of our customers’ unique environments. Which means we’re also going to be spending a lot of time getting to know you. All the more reason why we don’t want to waste time journeying on paths to nowhere.
From an integrations standpoint, this means we put vendor technologies (that we haven’t integrated) into three major buckets:
- We’re interested in building this integration (levels 3 & 4), but haven’t gotten to it yet. This is probably because we haven’t seen this widely deployed among our base of customers and prospects with whom we’ve spoken to date.
- We’ve decided not to build a direct integration, because we can access that data or support investigations as needed through a SIEM with which we integrate (level 2).
- We’ve decided not to build an integration at all (ever) because that data isn’t used often enough for the work to be worth it (level 1).

As everyone is well aware, the landscape of security technologies is immense and prioritization is critical – both for integrations and alerts themselves. Because technologies are always changing and growing, a given tech that we evaluated may have moved from one category to another.
If you ever feel like we’ve got an integration in the wrong bucket, we’re always willing to listen and re-evaluate.
I hope this helped shed some light on how and why we do things here at Expel – and maybe even inspired you to learn more. We’re always happy to chat.


")
