
TL;DR
- Increasing our analysts’ efficiencies by automating tasks has a direct effect on customer satisfaction, response time, and standardization, and is an integral part of the Expel data team’s mission.
- Key findings (KF) are text generated out of specific data, which makes it a great application for GenAI—we used large language models (LLMs) with carefully crafted chain-of-thought (CoT) prompt engineering.
- At Expel we AI Responsibly. This guarantees our customers’ privacy is paramount.
A key aspect of the Incident Reports we build for our customers is to summarize the key investigative findings. Generating these findings is a fitting application for GenAI, since it involves generating text from data gathered with Expel Workbench™, our SecOps platform. In this blog, we’re sharing a solution to generating key findings using LLMs to boost the productivity of our analysts. We’ll demonstrate how the technical solution involves instructing the LLM with a chain-of-thought (CoT) and examples from key findings generated by our analysts. We’ll also discuss the responsible AI approach at Expel, and the continuous improvement of our models. Overall, we believe GenAI is a great vehicle to improve analyst efficiency and enable them to dedicate time to creative thinking and critical solutions.
What’s key findings generation (KFG)?
An alert has a lifecycle—it surfaces in Workbench and is investigated. An investigation needs to cover all angles, be thorough, and detailed. Our analysts are creative in finding the clues, so we collect a rich amount of data to facilitate them. If an alert becomes an incident, we give our full consideration to investigating and ensuring the safety of our customer’s environment. This is when our analysts perform detailed research, then communicate in detail about their findings and recommend remediation actions.
Clear communication is important to Expel (and our customers), and it’s why we generate key findings reports that include all the questions we’ve answered during an investigation. This report is generated by the rich information Workbench collects, and the creativity and deep detective work our analysts perform. All of this is well and good, until you stop to think about who writes the report. This is where GenAI can help.
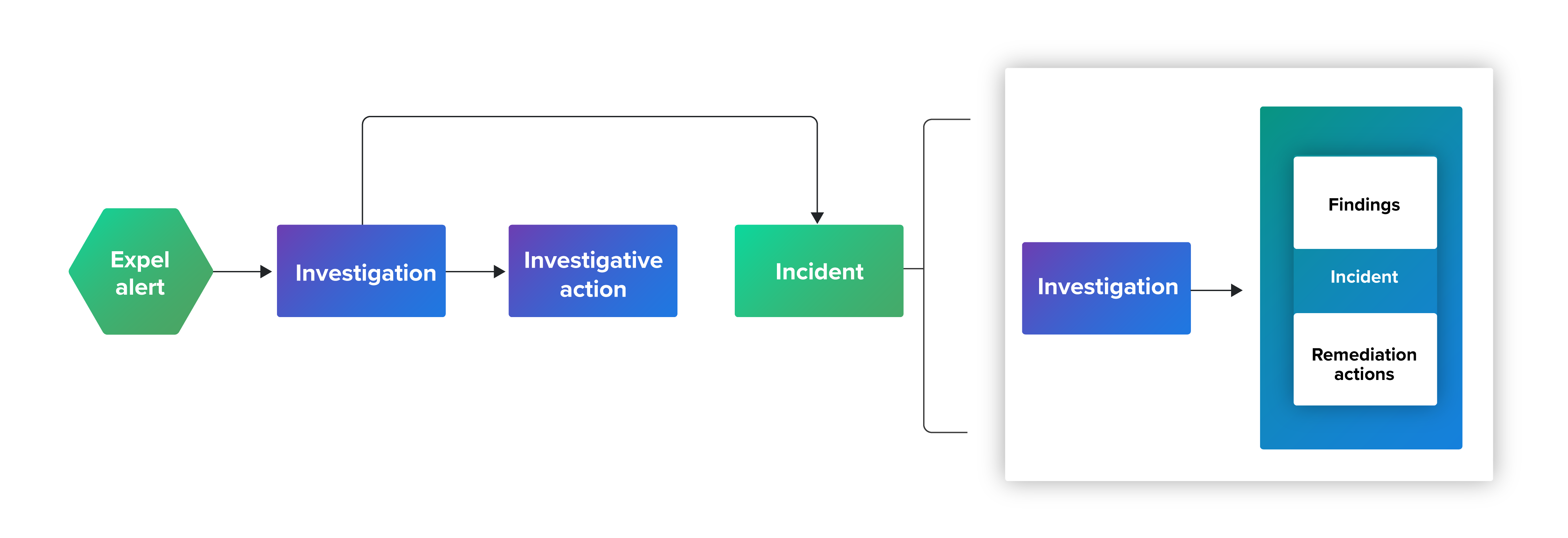
Why use GenAI for KFG?
There’s three main reasons we use GenAI to create key findings reports:
- Automation: At Expel, we constantly look for ways to improve how we serve our customers, so automating parts of our analysts’ work is paramount. By automating tasks, we’re increasing analysts’ productivity, freeing up time to investigate thoroughly, and preventing SOC burnout by offloading mechanical tasks. Deploying GenAI for KFG gives our analysts more time for creative work.
- Standardization: GenAI helps standardize communication, which is great for professional, complete reporting. Through standardization, we maintain high standards for our customers by ensuring a transparent, detailed, and consistent voice.
- Generation: Did you notice the word “generation” in GenAI’s name? KFG is text generation based on specific data, which is the perfect application for GenAI. (And using the right tool for the right job is what we do at Expel.)
How we did it
Any model—including GenAI—needs good data as input. In our case, the first part of the input to KFG is the rich data collected by Workbench. Specifically, we use alerts—generated by our own native detection and ingested from the security products we integrate with—remediation actions initiated by our analysts or executed by automation, and other key pieces of malicious activity identified by our analysts. From there, the data must be structured and clearly described. Sometimes, the model may not understand the data input, especially if we omit details related to the structure of the data. As a result, the model may encode the input data in a less representative manner. Good data representation means well-specified context, and therefore effective results.
The second part of the input is the prompt. This is the art and the science of KFG. In our case, we used a prompting strategy called chain-of-thought (CoT). CoT gives the model a peek into our analysts’ thoughts, with details on steps they take during investigations, and how they approach generating key findings. We enhanced the CoT prompt with examples from the best and most representative analyst-generated KFs (called Few-Shot prompting). Here’s an example of how this works:
| Prompt | Chain-of-thought | Few-shot |
|---|---|---|
|
Generate a key findings report based on the data below:
|
Generate a key findings report based on the data below:
Follow the steps below to generate your key findings:
|
Use the example report to generate a key findings report. The report is based on the example data. Example report: <KF1_from_analyst> Example data1:
… <additional examples> Generate a key findings report based on the data below:
|
Finally, we used Reinforcement Learning from Human Feedback (RLHF) to iterate on KFG. Our analysts provide feedback on which summaries were complete and correct, and whether there were hallucinations or inaccuracies. This technique leads to great improvements, since experts are the best judges for this type of application.

How we evaluated it
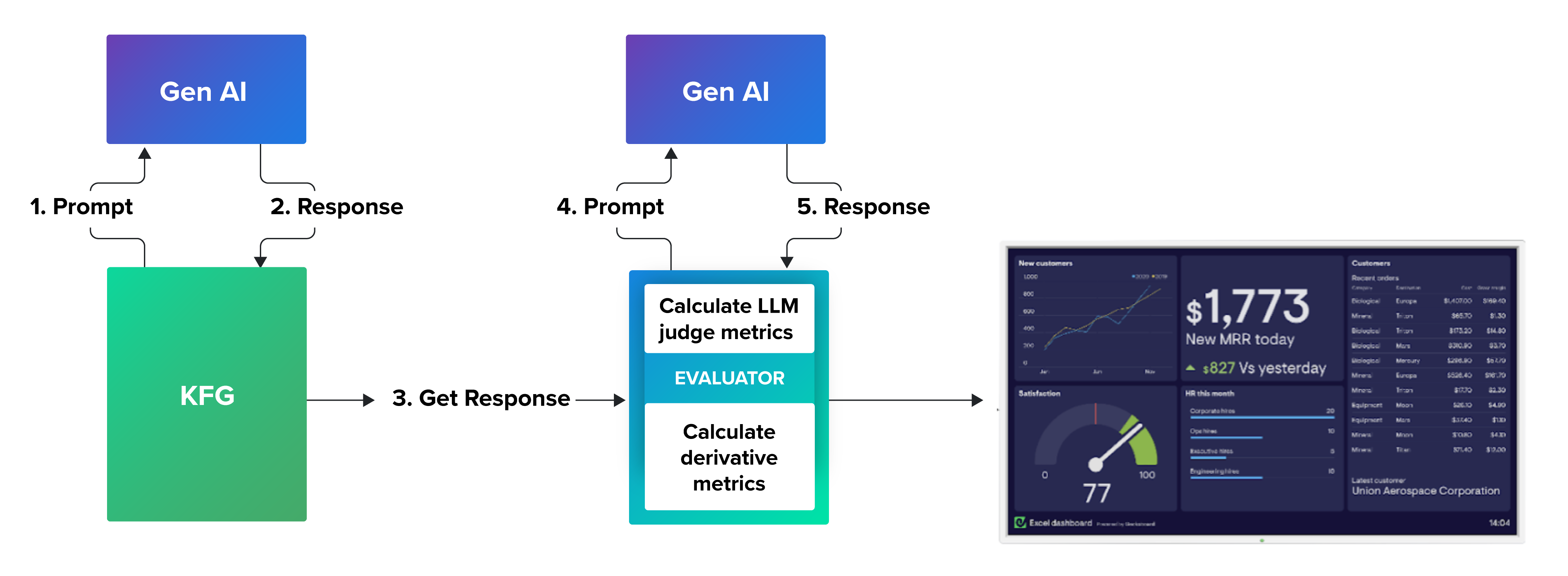
At Expel we have a saying: “if there is no metric, it does not exist!” In the case of KFG, it’s tough to measure how good the summaries are with objective, reproducible metrics, so we had to be inventive in our approach.
First, we created what we call “derivative metrics.” These were objective metrics related to how much information we used, how many syntax errors we made, and how much overlapping information we had. Then we used semantic metrics (such as BERT and ROUGE) to compare a set of model-generated KFs to analyst-generated KFs. Finally, we used an LLM as a judge. In this case, we had the LLM judge the completeness and correctness of the KFs using specific prompting instructions. This is a very promising technique we think can give a great boost to AI projects.
In the table below, you’ll see examples of derivative and semantic metrics. The first metric is a derivative metric for the completeness of the answer. It measures how many gaps we left in the model’s answer (i.e., unresolved variables left that weren’t populated with key findings). The model may add “N/A” instead of populating these variables, and we count this as a metric of incompleteness.
The second metric evaluates how many errors we made in the markdown syntax (the format we prefer for our key findings). Errors in markdown render improperly and lead to unprofessional-looking key finding outputs. Finally, the semantic metric BERT measures how close the model’s output is to a ground-truth output. In this case, we compare key findings generated by the model and key findings generated by a human. The BERT score uses deep learning to compare the meaning of words in context.
| Metric | Good output | Bad output | Value for good output | Value for bad output |
|---|---|---|---|---|
| Incomplete answer | The earliest evidence of red team activity occurred on July 10, 2014 at 00:44:09.000Z.
|
The earliest evidence of red team activity occurred on July 11, 2014 at 19:35:38.000Z.
|
0 | 6 |
| Markdown error count | The earliest evidence of attacker activity occurred on December 8, 2013.
|
|
0 | 2 |
| BERT | The earliest evidence of red team activity occurred on March 13, 2010 at 18:51:34 UTC.
|
The earliest evidence of red team activity occurred on March 13, 2010 at 18:45:00.
|
0.91 | 0.88 |
At Expel, We AI Responsibly
Our highest priority is protecting our customers’ privacy and data. We use AI with well-defined processes to avoid data leakage, meaning we:
- Use Expel-deployed models instead of public models. This gives us control over the model, which is non-negotiable when streaming sensitive data.
- We anonymize data so it isn’t used in the output of our KF GenAI report. We also filter PII data as well to secure any potential leaks.
- We don’t use third-party vendors where customer data is sent outside of our environment.
- With text generation work specifically, we keep humans in the loop to ensure customers don’t experience the bad side effects that come with typical LLM use. This means we spend fewer developer cycles playing Whac-A-Mole with guardrails when we ask LLMs to automate too much too fast.
What’s next with GenAI and Expel?
As one of the first MDRs to integrate machine learning (ML) into our workflows, our use cases have always been about improving response times for our customers, which is a result of our focus on easing the analyst experience. Capitalizing on this experience and our commitment to innovate, the sky is the limit with GenAI for SOC and MDR efficiencies. Our primary goal has always been to automate the boring things with LLMs so our analysts can spend time on creative activities like investigating alerts, finding perpetrators, and giving tactical and useful remediation actions to our customers.


")
