
We use a GitOps workflow. In practice, this means that all of our infrastructure is defined in YAML (either plain or templated YAML using jsonnet) and continuously applied to our Kubernetes (k8s) cluster using Flux.
Initially, we set up Flux v1 for image auto updates. This meant that in addition to applying all the k8s manifests from our Git repo to the cluster, Flux also watched our container registry for new tags on certain images and updated the YAML directly in that repo.
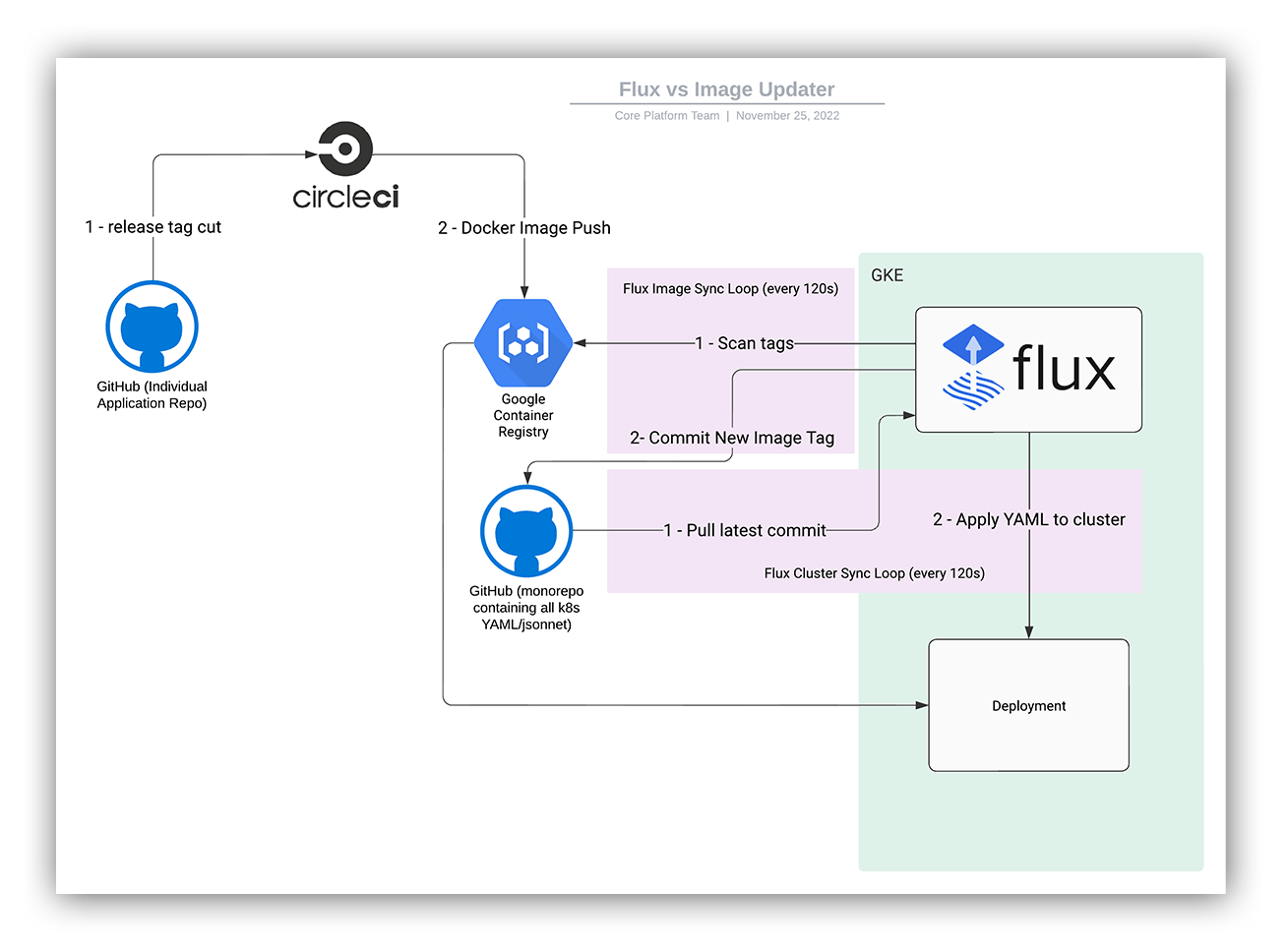
This seems great on paper, but in practice it ended up not scaling very well. One of my first projects when I joined Expel was to improve the team’s visibility into the health of Flux. It was one of the main reasons that other teams came to the #ask-core-platform Slack channel for help. Here are a few such messages:
- Is Flux having issues right now? I made an env var change to both staging and prod an hour ago and I’m not seeing it appear in the pods, even after restarting them
- Could someone help me debug why my auto deploys have stopped?
- Hi team, Flux isn’t deploying the latest image in staging
- Hi! Is Flux stuck again? Waiting 30m+ on a deploy to staging
Deployment smoketest
We decided to build a deployment smoketest after realizing that Flux wasn’t providing enough information about its failure states. This allowed us to measure the time between when an image was built and when it went live in the cluster. We were shocked to find that it took Flux anywhere between 20 to 45 minutes to find new tags that had been pushed to our registry and update the corresponding YAML file. (To be clear, Flux v1 is no longer maintained and has been replaced with Flux v2.) These scalability issues were even documented by the Flux v1 team. (Those docs have since been taken down, otherwise I would link them.) I believe it was because we had so many tags in Google Container Registry (GCR), but the lack of visibility into the inner workings of the Flux image update process meant that we couldn’t reach any definitive conclusions. We were growing rapidly, teams were shipping code aggressively, and more and more tags were added to GCR every day. We’re at a modest size (~350 images and ~40,000 tags). I did some pruning of tags older than one year to help mitigate the issue, but that was only a temporary fix to hold us over until we had a better long-term solution.
The other failure state we noticed is that sometimes invalid manifests found their way into our repo. This would result in Flux not being able to apply changes to the cluster, even after the image had been updated in the YAML. This scenario was usually pretty easy to diagnose and fix since the logs made it clear what was failing to apply. Flux also exposes prometheus metrics that expose how many manifests were successfully and unsuccessfully applied to the cluster, so creating an alert for this is straightforward. Neither the Flux logs nor the metrics had anything to say about the long registry scan times, though.
Image updater
We decided to address the slow image auto-update behavior by writing our own internal service. Initially, I thought we should just include some bash scripts in CircleCI to perform the update (we got a proof-of-concept working in a day) but decided against it as a team since it wouldn’t provide the metrics/observability we wanted. We evaluated ArgoCD and Flux v2, but decided that it would be better to just write something in-house that did exactly what we wanted. We had hacked together a solution to get Flux v1 to work with our jsonnet manifests and workflow, but it wasn’t so easy to do with the image-update systems that came with ArgoCD and Flux v2. Also, we wanted more visibility/metrics around the image update process.
Design and architecture
This relatively simple service does text search + replace in our YAML/jsonnet files, then pushes a commit to the main branch. We decided to accomplish this using a “keyword comment” so we’d be able to find the files, and the lines within those files, to update. Here’s what that looks like in practice for yaml and jsonnet files.
image: gcr.io/demo-gcr/demo-app:0.0.1 # expel-image-automation-prod
local staging_image = ‘gcr.io/demo-gcr/demo-app:staging-98470dcc’; // expel-image-automation-staging
local prod_image = ‘gcr.io/demo-gcr/demo-app:0.0.1’; // expel-image-automation-prod
We also decided to use an “event-based” system, instead of one that continuously polls GCR. The new system would have to be sent a request by CircleCI to trigger an “image update.” The new application would have two components, each with its own responsibilities. We decided to write this in Go, since everyone on the team was comfortable maintaining an internal Go service (we already maintain a few).
Server
The server would be responsible for receiving requests over HTTP and updating a database with the “desired” tag of an image, and which repo and branch we’re working with. The requests and responses are JSON, for simplicity. We use Kong to provide authentication to the API.
Syncer
The syncer is responsible for implementing most of the “logic” of an image update. It first finds all “out of sync” images in the database, then it clones all repos/branches it needs to work with, then does all the text search/replace using regex, and then pushes a commit with the changes to GitHub.
We decided to use ripgrep to find all the files because it would be much faster than anything we would implement ourselves.
We try to batch all image updates into a single commit, if possible. The less often we have to perform a git pull, git commit, and git push, the faster we’ll be. The syncer will find all out of date images and update them in a single commit. If this fails for some reason, then we fall back to trying to update one image at a time and creating a commit + pushing + pulling for each image.
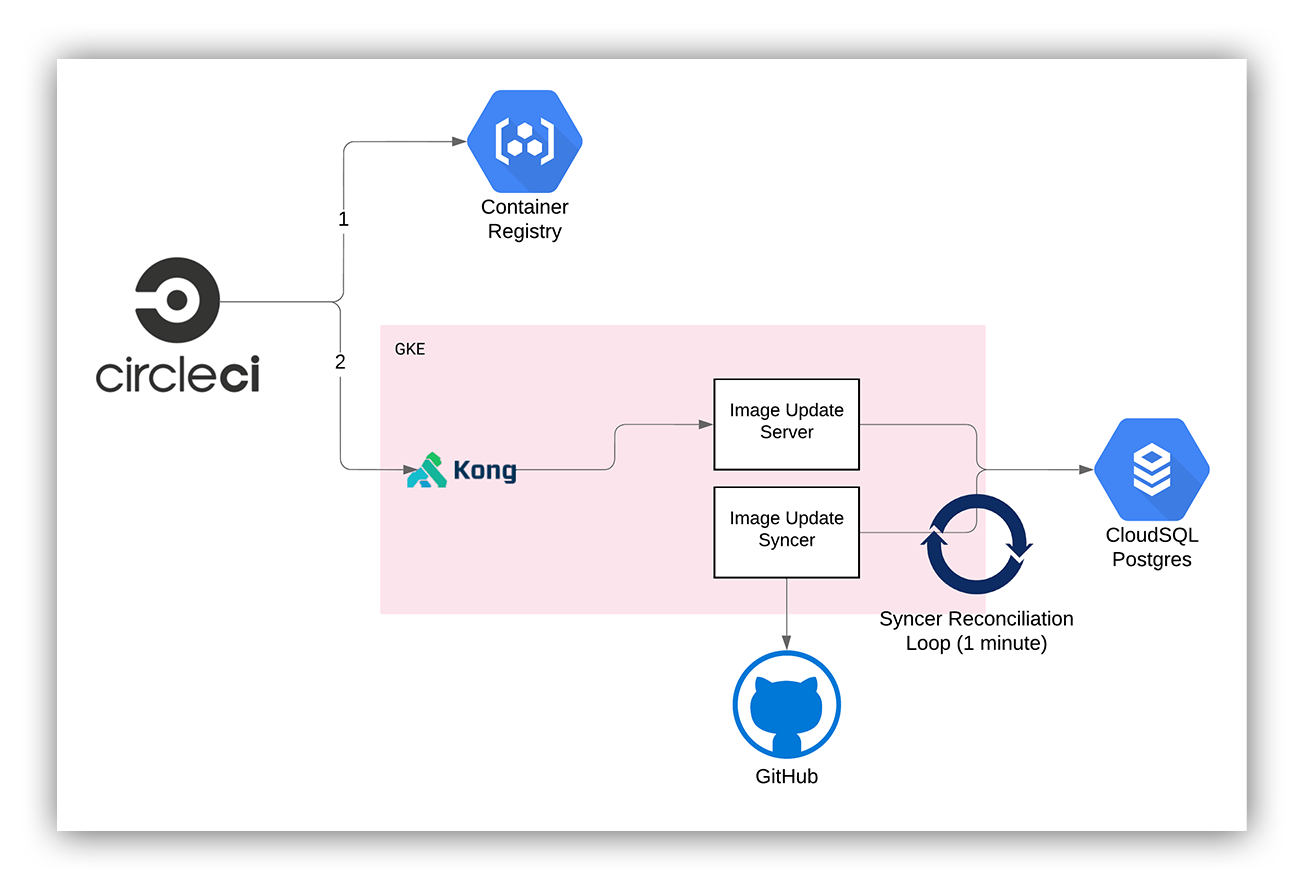
This is how image-updater fits into our GitOps workflow today.
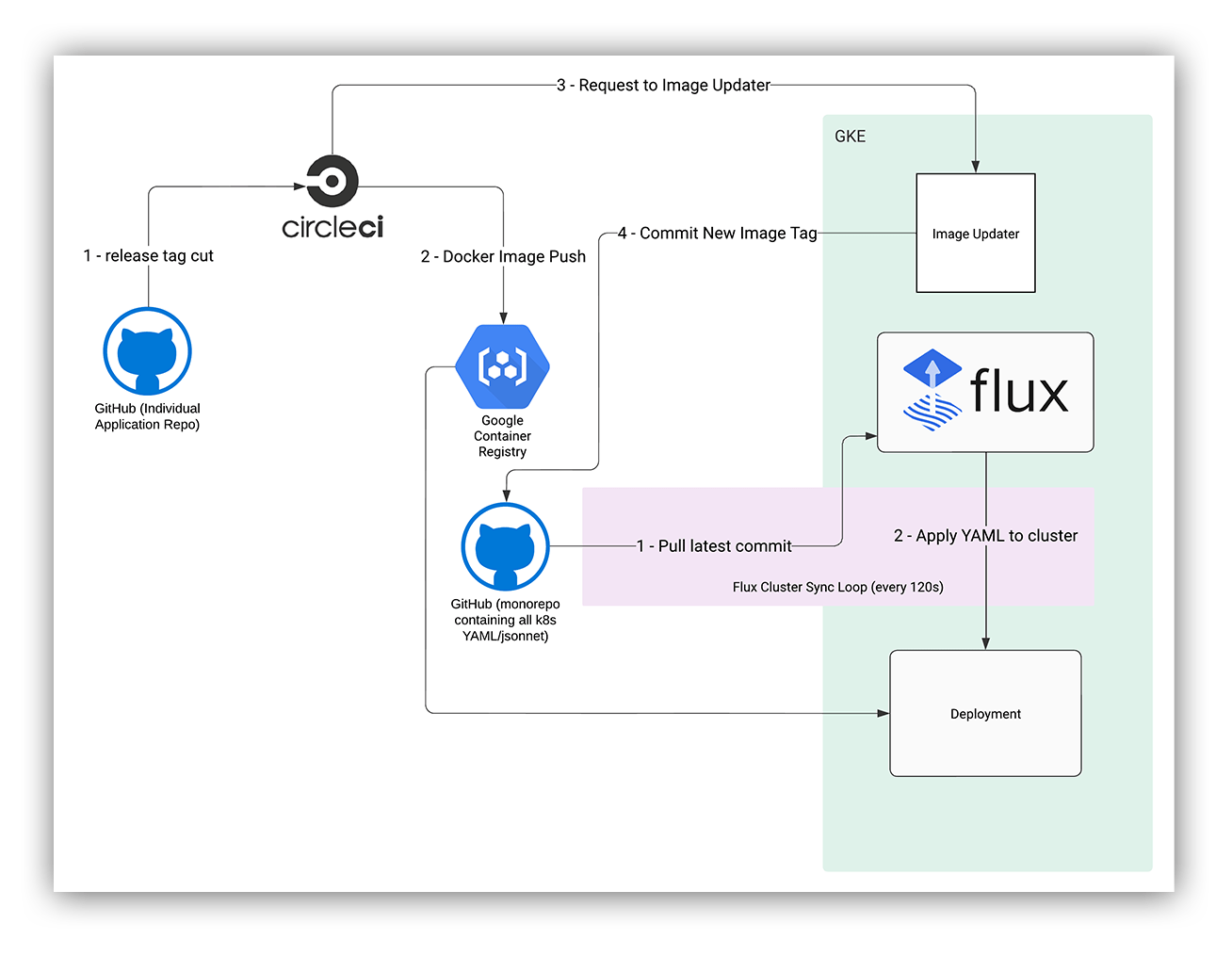
Improvements
Performance
Performance is obviously the main benefit here. The image update operation takes, on average, two to four seconds. From clicking release on GitHub to traffic being served by the new replica set usually takes around seven minutes (including running tests/building the docker image, and waiting for the two- minute Flux cluster sync loop). The image-update portion of that takes only one sync loop, which runs every minute. Hence, 45 minutes to one 🙂. We’re still migrating folks off of Flux and onto image-updater, but as far as we can tell, things are humming away smoothly and the developers can happily ship their code to staging and production without having to worry about whether Flux will find their new image.
Observability
The nice thing about writing your own software is that you can implement logging and metrics exactly how you’d like. We now have more visibility into our image update pipeline than ever. We implemented tracing to give us more granular visibility into how long it takes our sync jobs to run.
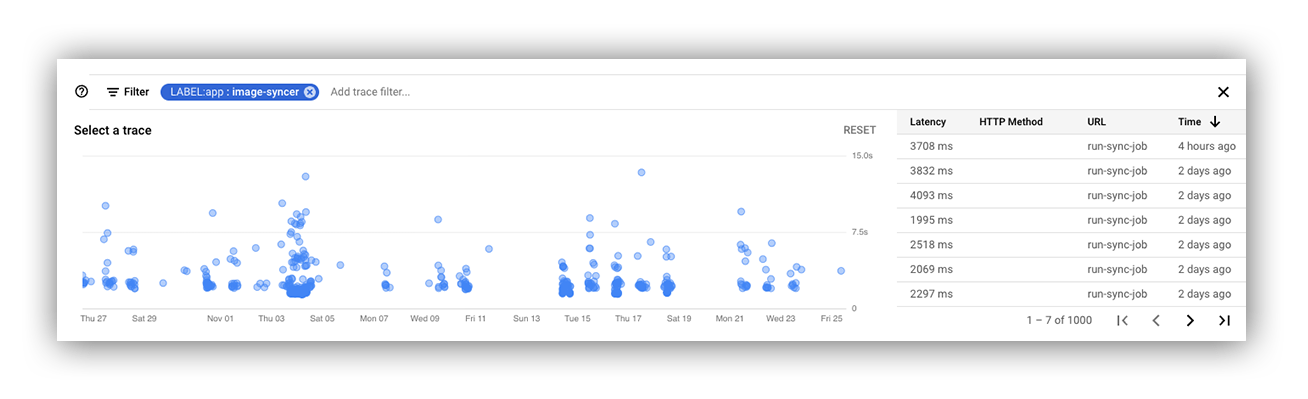
This allows us to identify bottlenecks in the future if we ever need to, as we can see exactly how long each operation takes (git pull, git commit, find files to update, perform the update, git push, etc).
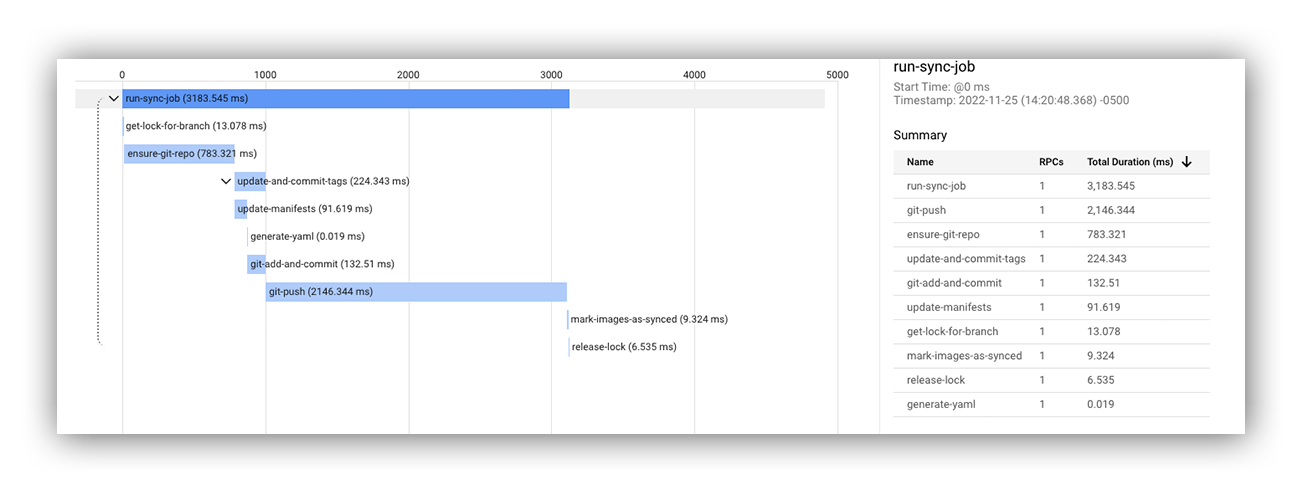
As expected, the git pull and push operations are the most expensive.
We also have more visibility into which images are getting pushed through our system.
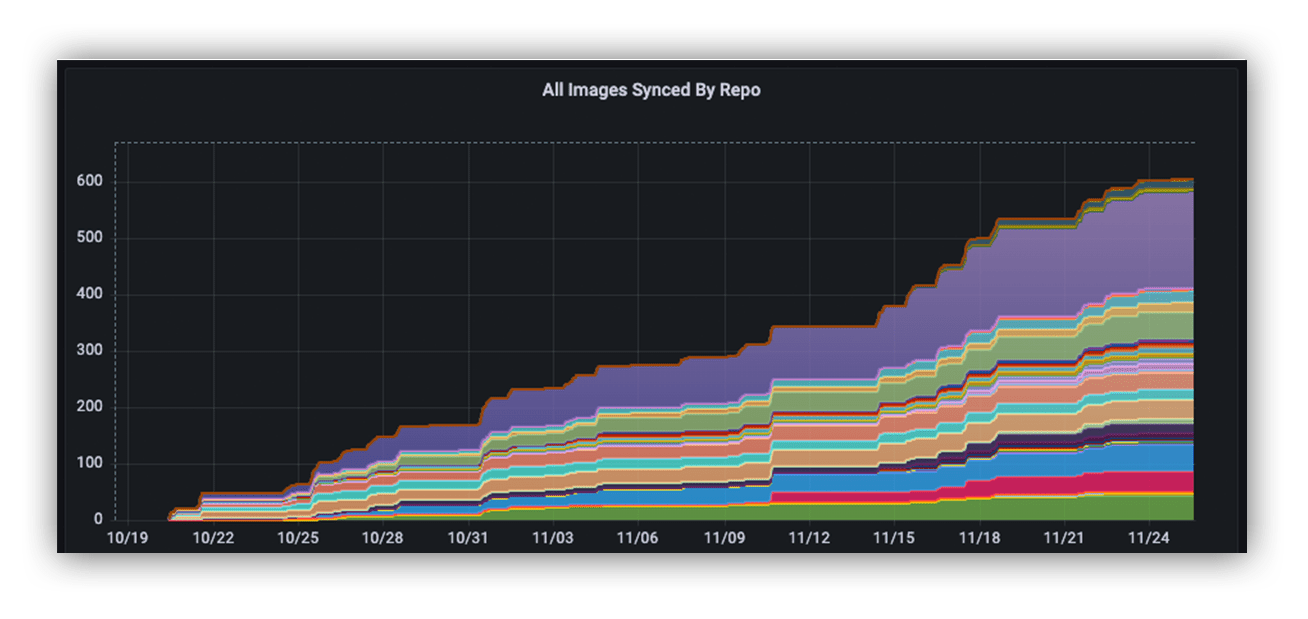
We implemented structured logging that follows the same pattern as the rest of the Go applications at Expel. We now know exactly if/when images fail to get updated and why, via metrics and logs.
jsonnet
This system natively supports jsonnet, our preferred method of templating our k8s YAML. Flux v1 did not natively support jsonnet. We even made a few performance improvements to the process that renders our YAML along the way.
Plans for the future
Flux v1 is EOL so we’re planning on moving to ArgoCD to perform the cluster sync operation from GitHub. We prototyped ArgoCD already and really like it. We’ve got a bunch of ideas for the next version of image updater, including a CLI, opening a pull request with the change instead of just committing directly to main, and integrating with Argo Rollouts to automatically roll back a release if smoketests fail.


")
