Machine learning in cybersecurity is a subset of AI that involves training algorithms on historical threat data to recognize patterns associated with attacks, enabling systems to detect novel threats without relying solely on predefined rules. It’s a key driver of modern detection capabilities, particularly for identifying subtle or previously unseen attack behaviors.
Key takeaways
- Machine learning is what lets security systems learn from data instead of following rules someone wrote in advance. That’s what makes it possible to detect novel threats—ones no rule explicitly covers—and get more accurate over time as more data accumulates.
- ML and rule-based detection aren’t competing approaches—they’re complementary. Rules win on precision and transparency for known threat patterns; ML wins on adaptability and scale for everything else. Strong detection programs use both.
- Training data is everything. A model is only as good as what it was trained on—if the data is stale, unrepresentative, or mislabeled, the model will be too. When evaluating ML security claims, ask about training data volume, recency, and what environments it came from.
- ML models degrade over time if you don’t maintain them. Environments change, attacker techniques evolve, and a model trained on last year’s data gradually loses accuracy. Ongoing monitoring and retraining aren’t optional—they’re part of the cost of running ML in production.
- High confidence from a model doesn’t mean correct. Adversarial inputs, edge cases, and training gaps can produce confidently wrong outputs. Analyst review at the right points isn’t a workaround for immature AI—it’s how responsible ML deployment works.
What machine learning is and how it differs from traditional programming
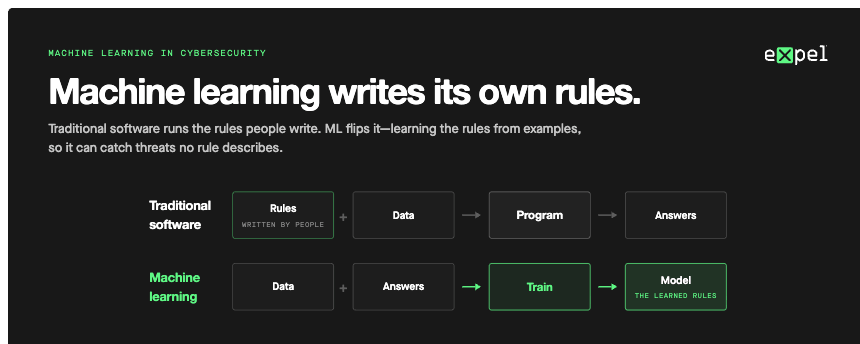
Traditional security software is explicitly programmed: developers write rules that define every scenario the system should handle. Effective but rigid, the system handles exactly what it was programmed for, and nothing else.
Machine learning in cybersecurity inverts this. Rather than programmers defining the rules, ML algorithms learn patterns from data. Feed a supervised learning model thousands of examples of malicious network traffic and thousands of examples of benign traffic, and the model learns to distinguish between them, including for traffic patterns not in the training set.
The practical security implication is significant: ML-based detection can recognize novel attack techniques that no rule explicitly covers, adapt as attacker behavior evolves, and improve accuracy over time as more data accumulates. The tradeoff is that ML systems are less predictable and transparent than rule-based systems. Understanding exactly why a model made a specific decision requires explainability investment.
ML is the foundation; for where AI in cybersecurity is heading, see agentic AI.
Types of machine learning in security applications
Supervised learning trains on labeled data, or examples where the correct answer is known. In security, this means training on datasets of labeled malicious and benign events. The model learns patterns that distinguish the two categories and applies that learning to classify new, unlabeled events. Effective for known threat categories where labeled training data is available; limited by the quality and breadth of labels.
Unsupervised learning finds patterns in unlabeled data, and discovers clusters and anomalies without predefined categories. In security, unsupervised learning powers behavioral baselines and anomaly detection: the model discovers what normal looks like and flags deviations. Doesn’t require labeled examples of attacks, making it effective for detecting novel threats.
Semi-supervised learning combines labeled and unlabeled data by using a small set of labeled examples to guide pattern discovery in a much larger unlabeled dataset. Useful when labeled attack data is limited (as it often is for novel threat types).
Reinforcement learning trains systems through reward-based feedback, and the system learns which actions produce desired outcomes by receiving feedback on its decisions. Emerging applications in security include adaptive response automation and adversarial simulation.
Common ML techniques in cybersecurity
Decision trees and random forests are widely used for alert classification and threat scoring. Interpretable (you can trace the decision path), robust to noisy data, and computationally efficient for real-time classification. Random forests (ensembles of many decision trees) improve accuracy by combining multiple models’ votes.
Gradient boosting (XGBoost, LightGBM) is a powerful ensemble method that builds models sequentially, each correcting the errors of the previous. Often achieves top performance on structured security data classification tasks.
Neural networks excel at recognizing complex patterns in high-dimensional data, and are particularly useful for malware analysis (examining binary code), network traffic classification, and natural language processing for phishing and threat intelligence analysis.
Clustering algorithms (k-means, DBSCAN) group similar events together are useful for identifying related attack activity, grouping alerts from the same campaign, and discovering anomalous clusters in large datasets.
Training data requirements and quality challenges
ML models are entirely dependent on their training data, because the patterns they learn reflect the data they were trained on, with all its limitations.
Volume: Most ML models require large datasets to learn reliable patterns. Training a malware classifier on a few hundred examples produces an unreliable model; training on millions produces a robust one.
Quality: Noisy labels (training examples that are incorrectly labeled as malicious or benign) degrade model accuracy. Data quality is often more important than data volume.
Representativeness: Models trained on data from one environment may perform poorly in another. An ML model trained primarily on enterprise Windows environments may miss threats targeting Linux or cloud-native workloads.
Recency: Attacker techniques evolve. Models trained on data from two years ago may miss techniques developed since then. Regular retraining with recent data is essential for maintaining detection accuracy.
Limitations of ML in security
Hallucinations: ML models can confidently produce incorrect outputs—fabricating patterns, misattributing activity, or generating plausible-sounding but factually wrong results. In security ML applications, this means model outputs require human validation rather than unconditional trust.
Adversarial ML: Attackers can deliberately craft inputs designed to evade ML classifiers by subtly modifying malware samples, mimicking normal traffic patterns, or exploiting model blind spots. As ML becomes more prevalent in security, adversarial evasion becomes a growing concern.
Model drift: Environments change; models trained on historical data gradually become less accurate as the environment diverges from their training distribution. Models need ongoing monitoring and periodic retraining.
Explainability: Complex ML models, particularly deep neural networks, are difficult to interpret. Understanding why a model flagged a specific event is important for analyst trust and investigation. Explainability investment is required for production security AI.
Overconfidence: ML models can produce high-confidence wrong answers. Treating high model confidence as certainty—without human review—is a mistake that adversarial inputs and edge cases regularly exploit.
ML in practice: How MDR providers use it
MDR providers are among the most intensive users of ML in cybersecurity because the scale of their operations demands it. ML powers alert triage (classification models that score alerts by threat likelihood), behavioral analytics (unsupervised models that baseline customer environments), correlation (models that link related events across data sources), and investigation automation (models that predict investigation paths and gather relevant evidence).
The cross-customer advantage is particularly significant: MDR providers train ML models on threat data from many customer environments simultaneously, producing models that recognize attack patterns no single organization’s data would reveal.
Expel’s take
The most common mistake we see when organizations evaluate ML-based security claims is treating vendor confidence as a proxy for model accuracy. A vendor can say their model is “AI-powered” without being able to tell you what it was trained on, how recently it was retrained, or what its false positive rate looks like in production. When we built Ruxie, our AI SOC manager, we started with real incident data from actual customer environments—not synthetic datasets. That training foundation is what makes the difference between a model that works in a demo and one that catches real threats at 3am. When you’re evaluating any ML security claim, ask for the number they’re willing to put in writing: false positive rate, detection accuracy, and how often the model gets retrained.
Frequently asked questions
What is the difference between machine learning and AI in cybersecurity?
Machine learning is a subset of AI where systems learn from data to improve performance without being explicitly programmed. In cybersecurity, ML is the primary technique used for threat detection, while AI is the broader concept encompassing ML, deep learning, and NLP.
How does machine learning detect malware?
Machine learning detects malware by analyzing file characteristics, behavioral patterns, network communications, and code structure—classifying samples as malicious or benign based on patterns learned from millions of historical examples, including novel variants that evade signature-based tools.
What is anomaly detection machine learning in security?
Anomaly detection ML establishes statistical baselines for normal behavior across networks, users, and systems, then identifies statistically significant deviations that may indicate threats. It excels at detecting insider threats, compromised accounts, and novel attack patterns.
What are the limitations of machine learning in cybersecurity?
ML limitations include adversarial attacks designed to fool models, dependence on representative training data, model drift as threats evolve, limited explainability of decisions, and false positives in environments with high legitimate activity variance.
How is machine learning used in MDR services?
In MDR services, ML models process telemetry across customer environments to detect threats, prioritize alerts, enrich investigations, and learn from analyst feedback. Cross-customer ML training enables detection of threats seen in one environment to protect all environments.