
Transparency is hugely important in managed detection and response (MDR). Here’s why.
Years ago, before Expel, my co-founder Justin Bajko was listening to a prospect describing his previous experiences with managed security service providers. He wasn’t recounting a tale of joy. Instead he summarized at the end by saying, “It’s like a big black box where I pour money in on this end and nothing comes out the other end.”
It’s a real problem. There are a variety of business functions that, when performed well, are somewhat invisible. When IT “just works,” do you notice it’s there? It seems like the only times you notice IT working is when it, in your experience, usually doesn’t. “Wow, my AirPods picked the right device this time, amazing!”
Security services that defend against adversaries are even more challenging, especially when a significant part of the value they provide is in detecting and stopping the adversaries before they can do harm. But what if the adversaries don’t show up? Was there any value?
We decided the answer, when we started Expel, was to tear open the black box and make transparent what’s inside. It started innocently enough—our erstwhile CTO looking to hone in on the minimum viable product asked off-handedly, “Everywhere I’ve worked there’s been an internal tool and an external portal—it sure would save us a lot of time if we only had to build one.”
What would happen if security analysts and customers could see the same things happening in real-time? That seemed scary for the security analysts—what if they make mistakes? Would their fear negatively impact the work, or would it drive quality and fuel career growth? And if we made the system transparent, could our customers click the same buttons we could click? The more we thought about it, the more we were convinced this is what the industry needed.
At that moment, transparency became one of our core tenets. It influenced not only how we built our products, but how we interacted with each other, how we designed our compensation systems, and how we work to this day with our customers and prospects.
What happens without transparency
Everything doesn’t always go right, especially when you’re trying to do something new or different. What we’ve discovered though is that despite our concerns, transparency doesn’t spark fear that lowers quality—instead, it shines a light on what’s working and what’s not in a way that drives continuous improvement.
Environments without transparency lack this catalyst. That’s not to say that such environments don’t see any improvement, it just means you have to rely a little more on the mindset of individuals and a lot of luck. Missing a culture of transparency makes mistakes more scary as you grow. With the best of intentions, people hide mistakes, preventing the organization from building support structures to mitigate them. As a result, the organization learns less and advances more slowly.
Transparency: three use cases
I think about transparency on three different levels: basic awareness, being able to stand up to inspection, and proactive ownership under adversity.
Is this thing on?
Remember the black box? If you pour something in on one end, you ought to be able to watch as it flows to this system.
Given that we process over 30B+ alerts and events per month from our customers and integrate with 120+ technologies, that’s a lot of flow to make transparent. It starts with the technologies themselves: understanding what’s connected, whether it’s configured correctly, and what data is flowing through it is table stakes.
While this sounds simple, I’m sure anyone reading this knows how hard it is to have full confidence that “it’s working.” Devices can go offline due to changes elsewhere on the network, updates can make an existing known-good configuration obsolete, and changes in traffic flows can make it awfully difficult to baseline what a “normal” traffic pattern looks like. Our device health team is perpetually focused on continuous improvement in this area, because it’s a moving target.
Summarize what happened
One of the challenges is that as transparency increases, the information you have available eventually exceeds your capacity to consume it. Now, instead of transparency answering your questions, it’s consuming your time.
The first step to addressing this is through summarization. In the managed security space, the most obvious example is the funnel. A large volume of signal goes in, it gets analyzed in several stages, through which the overall volume is reduced until ultimately (hopefully) the right signal is prioritized, analyzed, dispositioned, and acted upon. Being able to spit back out these and other numbers is one basic form of summary.
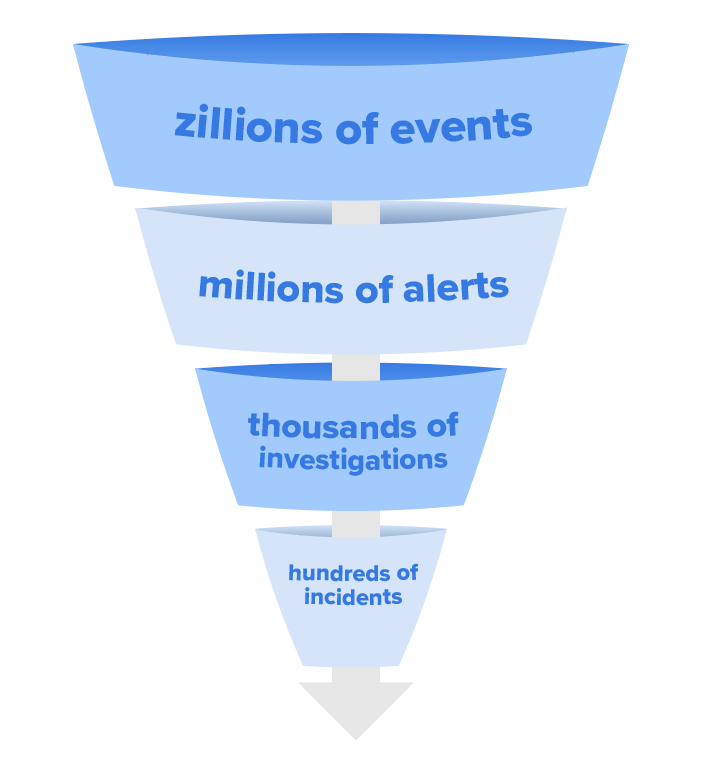
The most important work a security operations center (SOC) does, though, is analysis. Not everything needs analysis, of course—there’s a lot of noise surrounding the signal that matters. But when we’re dealing with something that might be malicious, you want to know what we did and why we did it. Things like investigative timelines and close reasons are critical here to gain confidence that the actions we’re taking are the correct ones.
And finally, when things pop off we have security incidents. All of the investigative transparency needs to be inherited into the incident and it’s vital to have both real-time visibility into the analysis taking place and summary information about what we know so far. One of the biggest advantages to how we’ve built Expel Workbench™ is how it makes this possible. You don’t have to wait for an incident report to be finalized. You don’t even have to wait for an incident to be declared—you can watch as things progress in real time.
But you don’t have to. You can still wait for the summary.
Transparency in failure
Perhaps the most brutal form of transparency is when it happens under a failure condition. People make mistakes. Part of leadership’s job is to build structure around the work so that the impact of those mistakes are mitigated. Any system that relies on the assumption that “nobody will make a mistake” is a system destined to fail.
As I mentioned earlier, transparency is the accountability lever that helps turn these mistakes into learning. Here are two examples.
Cascade failure
Years ago, we realized we could optimize our already-short onboarding process further by staging technology integrations so that the configuration work was done before the contract was signed. We’d just jam in a little configuration that would suppress the data flow and undo that when we turned on the service. You see where this is going, right?
Because it was early in our journey into this particular optimization we’d anticipated that someone might “forget,” and so we built monitoring systems to alarm when that happened. And you know what—two things happened at once. Not only did someone forget (which is okay—there’s too much to remember, anyway), a configuration change broke the monitoring that should have sent up an alarm.
Not great. We wrote up an after-action report to understand what happened and identify what we wanted to do differently to ensure that the same set of mistakes wouldn’t happen again. We then called the affected customer, let him know, and shared what we were going to do to make it right. He listened patiently, and after some short dialogue reflected, “You know, if you hadn’t told me about this I’d never have known right?”
“We know,” we said, “but we don’t sweep things under the rug here.” It’s not worth it.
We should have caught that
The more frightening problem in the security space is missing something you should have caught. This problem is so pervasive that the concept of “defense-in-depth” has been around for over a hundred years. We know that any given technology, any given person, any given system can fail. So we want another line of defense.
The stakes are high as an MDR provider because we’re one of the last lines of defense.
The approach we take to manage this is identical to the approach we take to drive operational efficiency in our SOC. We monitor, measure, and iterate.
Looking back over the last year, while incident counts have gone up 74%, the already low volume of customer-reported incidents has dropped by 46%.
How Expel measures
As our customer volume has gone up, so too has our incident count. If we think about one aspect of quality as the number of times a customer brought something to our attention instead of the other way around, we can look at that in proportion to our total number of incidents to see if we’re driving quality in the right direction. Does your managed service provider measure this? Without it, how can they possibly know whether their error rate is climbing, staying flat, or decreasing over time? We measure this as customer-reported incidents divided by total number of incidents, both SOC reported + customer reported.
This approach corrects for our growing customer base as well as our our varying customer size. (For example, a customer for whom we find 12 incidents a quarter and miss one, will likely feel better about that than a customer for whom we find one and miss one).
This is an incredibly useful signal we have that most detection and response teams don’t. Getting a second chance to hear about an incident helps us drive improvements in our detection program to better protect customers.
The results of transparency
Over time, we believe our focus on transparency has driven three important outcomes:
- It’s helped our customers hold us accountable, which has made us better.
- It’s engendered trust, which has made for stronger relationships.
- It’s been a lot less stressful because nobody’s hiding stuff.
That said, transparency isn’t all sunshine and rainbows.
Life after transparency
As I mentioned above, one challenge that arises out of transparency is that the wealth of information eventually becomes large enough you simply can’t transact on it.
Sometimes summarization works as a way to mitigate that, but then you lose visibility into the detail. To build and maintain trust, we’ve got to be able to answer both “how do you make these sorts of decisions?” and “why did you make that decision?”
And so, after transparency (with summarization) comes provability. You can’t just show it, you have to prove it. And that’s the journey we’re now on.
What happened to this?
Security operations is all about making decisions about what’s worth looking at and what’s not. If you make bad decisions here you’ll waste a lot of time chasing ghosts. But if you overcorrect, you’ll miss something important. So for any given “thing” you need to be able to see how it was handled, what decision was made, and why.
Above we covered investigations and incidents. In those scenarios, being able to watch an investigation unfold in real time, having access to a timeline of the investigation, and the ultimate disposition and findings report provide the needed visibility.
But what about signal that never makes it to a human being? How can we be confident that treating it like chaff was the right decision? Our most recent feature aimed at increasing alert transparency is Event Search. This lets our customers search by standardized fields in our evidence database for matches and see relevant events along with why they were or weren’t surfaced as alerts (plus other important details).
Proving it
We believe the proof is in the pudding and we’re excited to share with our customers and prospects what we’ve done and what’s coming. To that end, we invite you to watch a demo and check us out on YouTube. We look forward to getting to know you.


")
