
TL;DR
- Transparency is a core value at Expel. However, it’s generally a hard problem to explain why an alert is benign. To solve this, Expel created AI Resolutions (AIR).
- AIR is an AI-powered feature that uses a reasoning language model to analyze alert data and generate detailed, data-backed explanations for why a security alert was considered benign.
- Human judgment remains central to the process. An analyst reviews the AI-generated comment and can choose to use it fully, partially, or not at all, which also helps improve the model’s accuracy.
Transparency motivates us
At Expel, transparency is paramount. We strive to consistently share our findings with customers, meticulously explain the mechanics behind our MDR alerts, and openly communicate our detection philosophy. However, a common challenge arises when an alert triggers due to expected detection, yet the evidence, paired with a human analyst’s judgment, indicates benign activity. Proving the null—what isn’t present—and robustly justifying it with data is inherently difficult. To address this, we developed AI Resolutions (AIR), a new Expel Workbench™ feature. This feature leverages AI intelligence alongside our automation’s robust evidence collection to clearly explain why an alert is benign. This also supports transparency at scale, as it’s not feasible for our SOC to write these close comments manually for every benign alert.
What’s AI Resolutions (AIR)?
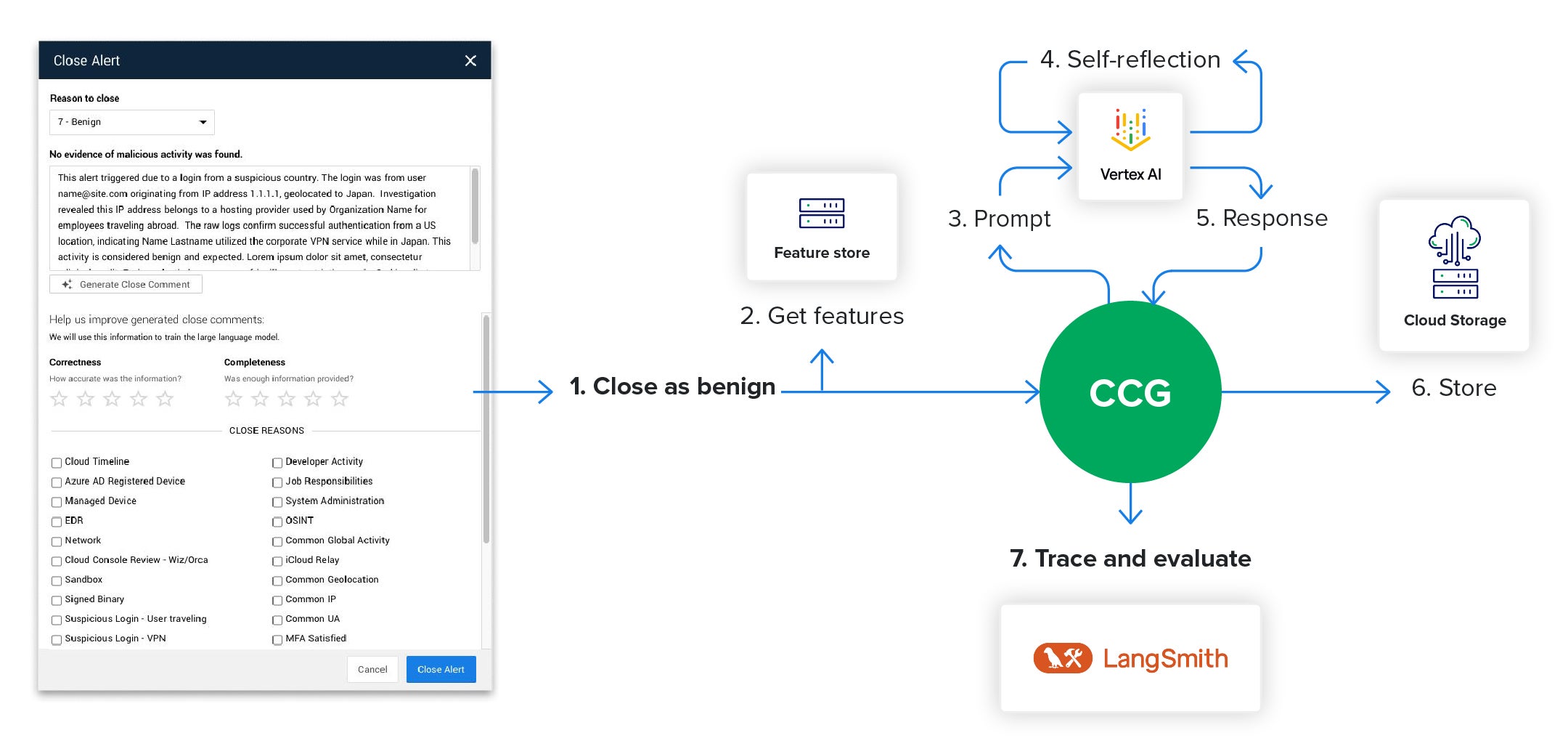
Expel MDR emphasizes transparency through AIR, a feature that delivers detailed closing explanations for benign alerts. At the heart of this process, a reasoning language model interprets alert data to generate detailed, data-backed justifications explaining why the activity was deemed benign. The AIR workflow, as depicted in the graphic below, functions as follows:
- Analyst decision: An analyst deems a Workbench alert benign.
- Workflow initiation: The AIR workflow starts after this decision.
- Data retrieval: The workflow first retrieves relevant data from the feature store, which holds model-ready data characteristics.
- AI inference request: The system then infers what the data means using a crafted prompt and data features to generate accurate close comments.
- Response storage: Finally, the workflow stores the response and triggers tracing and online evaluation* for continuous validation.
*Tracing and evaluation is a process for tracking model performance, errors, and inference quality metrics with each run, storing this data for review and improvement.
Ultimately, the analyst determines whether to fully adopt, partially use, or discard the close comment. This keeps human judgment in the loop and enhances model responses, as adoption rates are measured in our application.
Data and AI feasibility
At Expel, we believe in the strategic application of AI, rather than using it as a one-size-fits-all solution. When developing our close comment generation feature, we quickly realized the importance of avoiding generic approaches like templates, writing from scratch, or default close comments. This decision was crucial because:
- Templates and generic comments lacked the necessary detail and nuance. Our objective was to provide thorough explanations without being overly verbose, leveraging the rich data from Workbench. Templates or generic comments would inevitably fall short, as they can’t adapt to the unique characteristics of each alert and the specific context of threat detections or their absence. They would either be too vague to be useful or too rigid to accurately reflect the complex data points.
- Writing from scratch was inefficient and prone to inconsistency. Manually crafting detailed explanations for every close comment is a time-consuming process for our SOC analysts. This not only slows down operations, but also introduces inconsistencies in language, depth, and clarity across different analysts. The mission-critical nature of the application demanded a high level of uniformity and accuracy that manual, ad-hoc writing couldn’t guarantee.
- The need for precision and determinism superseded generalized approaches. Incorrect assumptions were unacceptable for our application. While LLMs have a non-deterministic nature, our design prioritized making the feature as deterministic and data-driven as possible. Templates or writing from scratch would rely heavily on human interpretation and potential biases, leading to a higher risk of error or misinterpretation. AI, when strategically applied with rigorous data and evaluations, offered a path to minimize these risks.
- Analytical use of data required more than simple reporting. Our process went beyond merely templating a report. It demanded the analytical use of data to justify conclusions. Neither templates nor manual writing from scratch could efficiently or reliably perform the deep analysis required to guide the LLM to correct inferences, especially when dealing with complex alert data. The ability to convert raw alert data into a structured format and then build a rigorous system to test, measure, and refine the output was a testament to the necessity of AI for this specific problem.
Accurate and concise alert data was crucial for guiding the LLM to correct inferences. Once we confirmed the data was suitable for this type of inference, we proceeded to the next stage: converting the data into features.
Having confirmed that an LLM was the right tool and that our data was suitable for the task, we moved from strategy to execution. The next step was to translate raw alert data into a structured format the model could understand and then build a rigorous system to test, measure, and refine its output.
In part two of this blog, we’ll dive into the technical details of how we engineered our data features, developed custom metrics for accuracy, and ran experiments to create a reliable and trustworthy AI system.



