
Product · 5 MIN READ · ANDERS BLAIR AND MATTHEW KRACHT · NOV 25, 2025 · TAGS: AI & automation / Get technical
TL;DR
- We developed an algorithm that makes our data polling more efficient, allowing us to ingest customer data faster while reducing the resources our pollers require.
- The algorithm is called Autotune, and is currently patent pending.
- It results in less resource consumption, saving time and money for our customers.
Polling, which is often used to keep information current in applications or systems, is the process of repeatedly requesting data from a server at regular intervals to check for updates or changes. We have more than 100 integrations with critical security and business applications, the majority of which depend on polling an API to retrieve alert data for Expel Workbench™. To ensure we’re ingesting new data as quickly as possible, we have a tasking system scheduling polling tasks on a regular basis. With so many integrations in place, some of which require multiple pollers, we typically have tens of thousands of polling tasks running at any given moment.
To ensure we ingest this new API data as quickly as possible, we built Autotune, a system that optimizes polling task efficiency, improving task speed, resource consumption, and network request performance.
Steps and the autotune algorithm
Each polling task has a designated time window. For example, let’s say we have a polling task that needs to query an API for alerts that occurred between 12pm and 3pm. How should the polling task send requests for that period of time? Should it send one request for the full three hours of time? Should it send a request for each hour (12pm-1pm, 1pm-2pm, and 2pm-3pm)?
This is determined by the step value, which is the increment of time we poll by. So if we’re polling a three-hour period and have a step value of one hour, we divide the period into three one-hour steps.
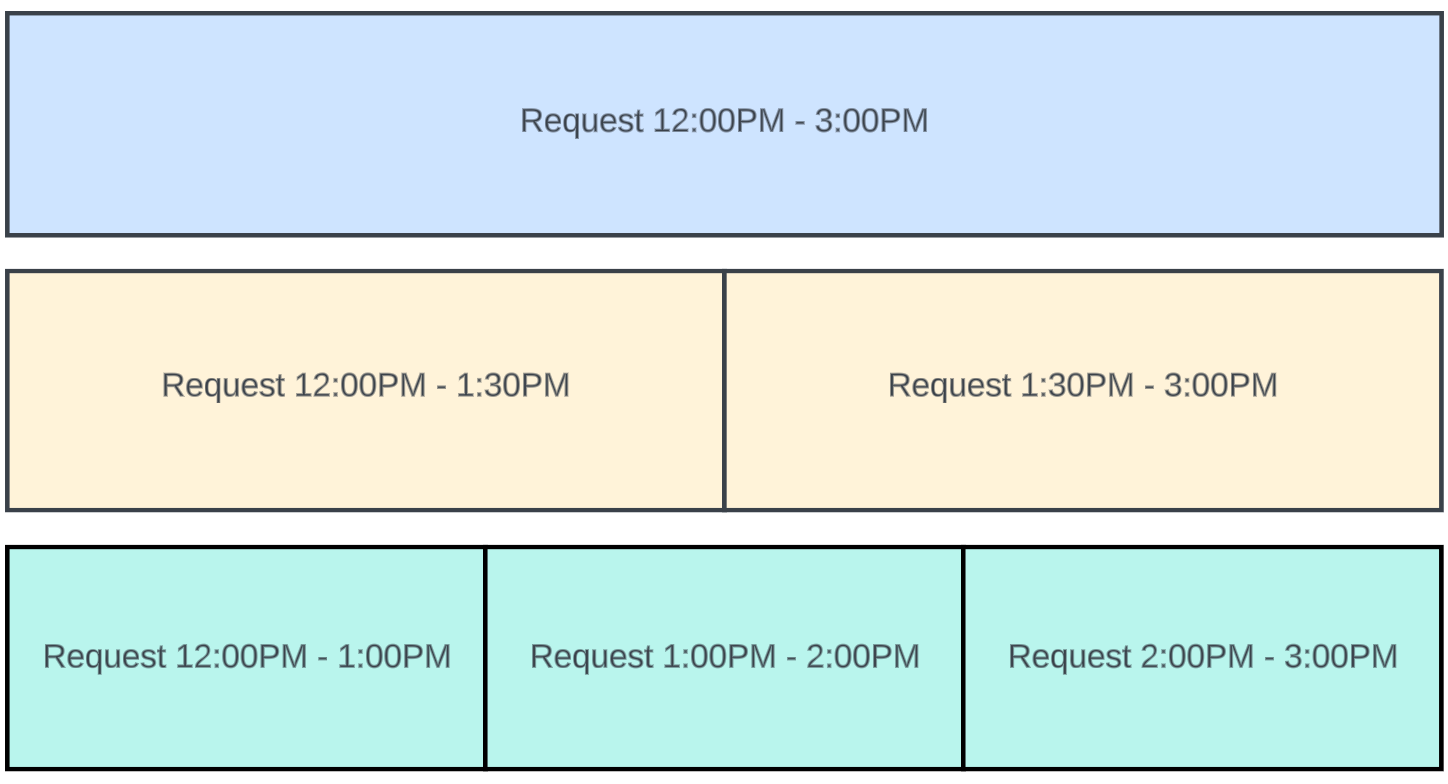
This diagram shows how a three-hour period of time can be divided into different steps determined by the step value used:
- Top blue bar: A three-hour step value is used, so we send one request to the API for three hours of alert data.
- Middle yellow bars: A 90-minute step value is used, so we send two requests to the API for one-and-a-half hours of alert data each
- Bottom green bars: A one-hour step value is used, so we send three requests to the API for one hour of alert data each
The size of the step value is critical. What if the step value is too large and we pull in so much data that we encounter memory issues? What if the amount of time it takes to complete each step means we can’t ingest alerts quickly?
Since every customer integration is unique, it can be a challenge to make sure each polling task is running optimally. So we devised an algorithm called Autotune. It collects metrics on how each step performs (how long did it take to complete the step, how much memory did the step use when polling, etc.) and then, given a set of timing and memory constraints, the algorithm determines the optimal step value. This value is then used on the polling task.
Some examples:
- If steps are using too much memory, Autotune might recommend reducing the value from an hour to 30 minutes (a shorter step value means we poll over shorter periods of time, and can then distribute memory usage across smaller steps).
- If steps are taking too long to complete, the algorithm will reduce the step value from three hours to one (a shorter value means quicker API responses).
- What if the steps are within the defined constraints? Autotune might increase the step value, cutting down the number of API requests we make.
Autotune benefits
Autotune’s ability to automatically tune the step value of individual pollers is important because each is unique. As noted above, too large a step value means we could run out of memory, take too long to complete a poll, or not ingest alerts quickly. Too small a step value might create an API rate limit issue (smaller step values = more API requests).
With so many individual customer integrations and different volumes of data coming in at different times, it’s impossible to manually tune each individual poller. Autotune reacts to each poller’s data, ensuring we’re always operating within memory and timing limits we set, thus getting alerts into Workbench as quickly and efficiently as possible.
As an additional benefit for those meeting the memory and timing limits we set (the majority of our alert pollers), Autotune makes the step value larger, cutting down on the number of API requests. It isn’t uncommon for us to get customer requests like, “Hey, you’re sending too many API requests, can you reduce the amount?” With Autotune, we can mitigate those requests by using a larger step value when we’re within the memory and timing limits.
Autotune in production: Success stories
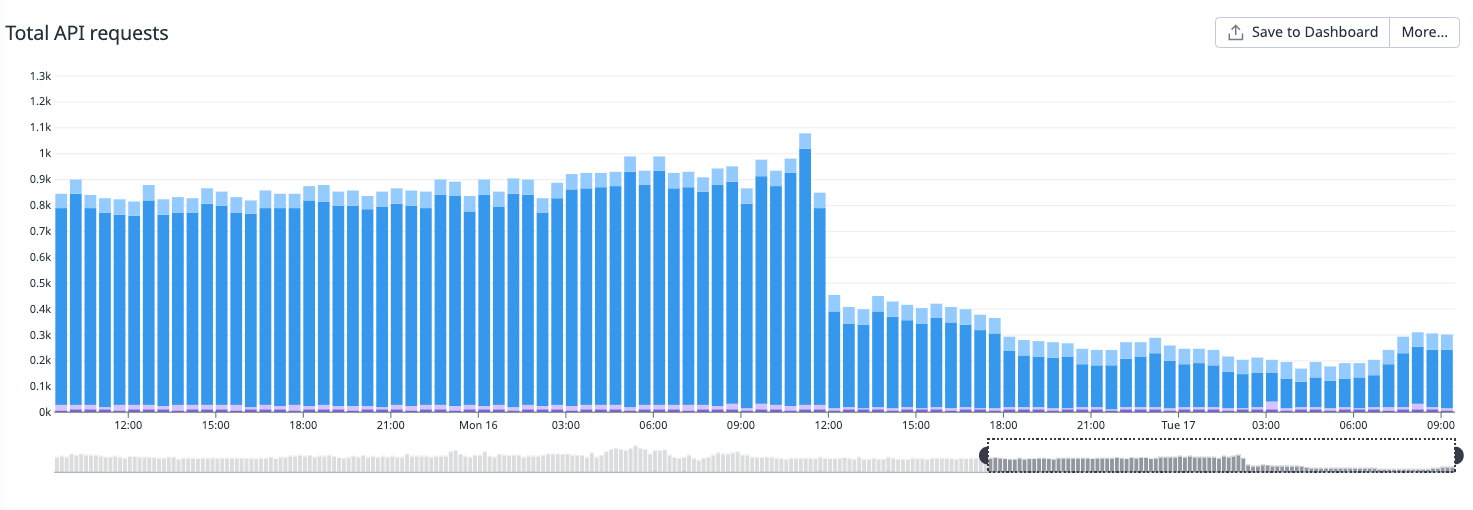
1. Reduced the number of API requests for one customer’s Microsoft Sentinel poller by half.
This poller’s steps were within set timing and memory constraints, so when Autotune was enabled, it increased the step value, leading to larger windows of polling time, which in turn means fewer API requests to get the same data.
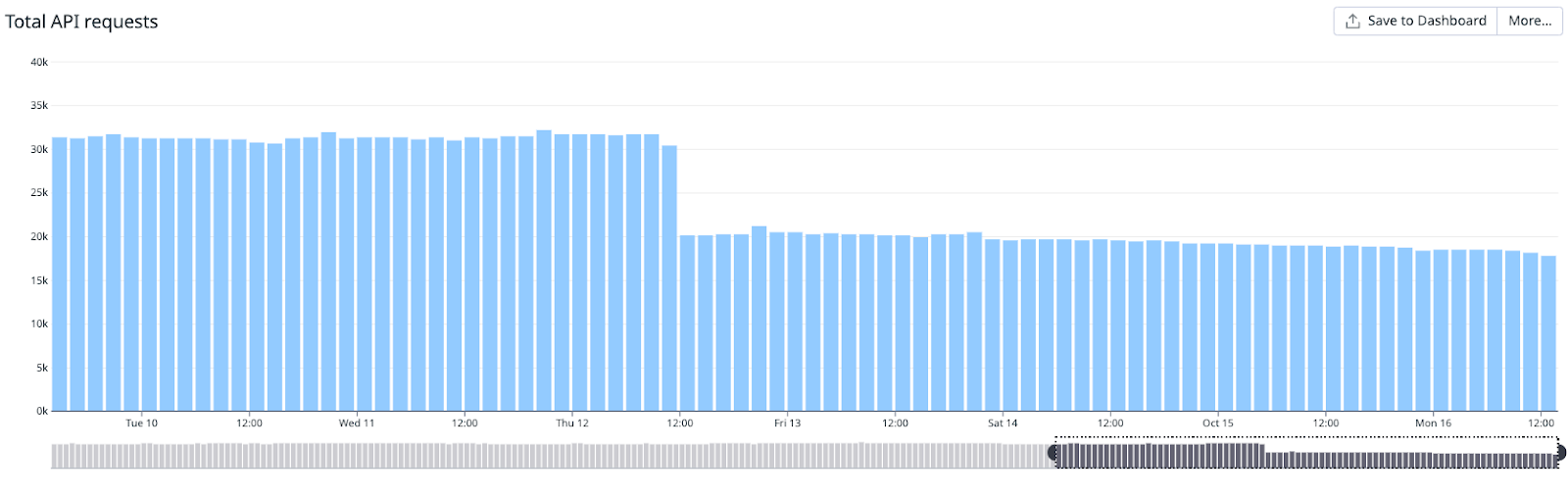
2. Reduced the number of API requests across all Microsoft Defender for Cloud Apps pollers by a third.
All of our Microsoft Defender for Cloud Apps pollers were within the timing and memory constraints we defined. When Autotune was enabled, it increased the step value, leading to larger windows of polling time, which means fewer API requests to get the same data.
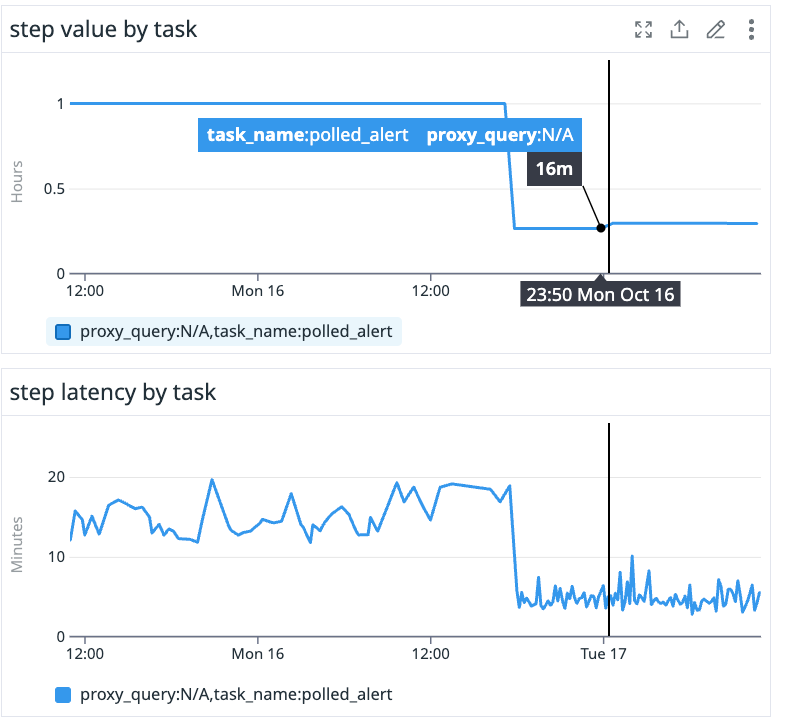
3. Reduced the time it took to complete steps for one customer’s Microsoft Sentinel poller by 15 minutes.
The poller was using the default step value of one hour (each integration has a different default step value—Netskope has a default step of ten minutes, for example, while Microsoft Sentinel has a default step of one hour). Autotune calculated the optimal step value to be 16 minutes. Before Autotune was enabled, it was taking upwards of 20 minutes to complete a step—now steps are consistently taking around five minutes to complete, which means we’re retrieving and uploading alerts into our system four times faster than before.
4. Reduced the memory consumption for steps completed by a customer’s Netskope poller by two thirds.
The poller was using Netskope’s default step value of 10 minutes and consuming upwards of 1.5 gigabytes of memory, which can cause problems. Autotune calculated the optimal step value to be around three minutes and now we have smaller and less variable memory consumption per step with each step consuming 500 megabytes or less of memory.
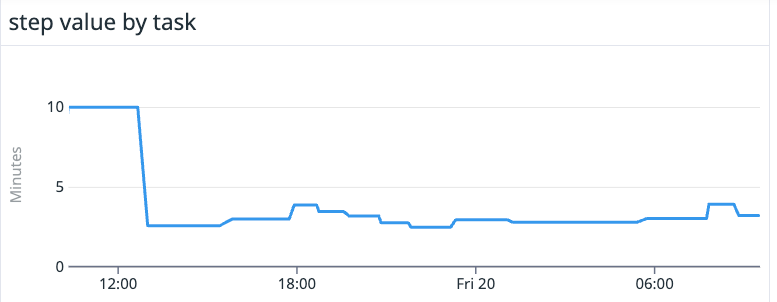
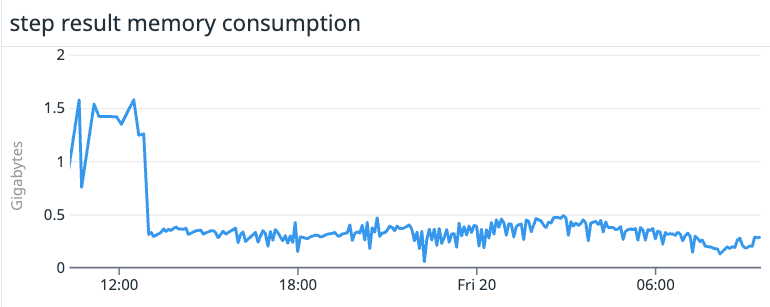
Autotune’s primary customer benefit: Decreased resource consumption
On self-hosted technology like a Palo Alto Networks firewall, Autotune lets us use fewer resources on the security device and lower the chance of disrupting normal operations on the device. And for some cloud technologies like Okta, Expel and the customer are both consuming the same API quota. When we use fewer API requests, it makes more resources available for customer uses.
Implementing Autotune allows us to ensure we’re ingesting alerts quickly when polling, have consistent memory consumption, and aren’t making unnecessary API requests. These optimizations mean as we grow in customer integrations, we can be confident we’re maximizing the amount of data taken in while still rapidly consuming and analyzing alerts as they become available on a given API. Autotune also allows us to reduce overall support load per customer integration because we no longer have to manage manual optimization.
All of this is to say we’re always striving to ensure we’re operating in our customers’ environments in the most efficient and effective way possible. Autotune is the latest in a long line of innovations that deliver useful, measurable cybersecurity outcomes for customers.



