Table of Contents
Alert fatigue happens when security analysts within a SOC become overwhelmed and desensitized by the sheer volume of security alerts they receive daily, leading them to miss genuine threats buried in false positives. This dangerous condition develops when poorly tuned security tools generate thousands of low-quality alerts, forcing analysts to spend their time triaging noise instead of investigating real incidents—ultimately degrading your organization’s security posture.
The consequences extend far beyond frustrated analysts. Alert fatigue directly contributes to missed threats, delayed incident response, and analyst burnout that drives costly turnover. Understanding what causes alert fatigue is the first step toward building more effective security operations to protect your organization without overwhelming your team.
In this article, we’ll explore the root causes of alert fatigue, how to recognize healthy versus unhealthy alert volumes, and practical strategies for reducing the false positives plaguing security operations.
What causes alert fatigue in security operations?
Alert fatigue stems from multiple interconnected factors compounding to create an unsustainable operational environment for security teams.
Misconfigured security tools are the primary culprit. When SIEM platforms, EDR solutions, firewalls, and other security technologies aren’t properly tuned for your specific environment, they flag normal business activities as suspicious. Out-of-the-box detection rules rarely work well without customization—they’re designed to be overly sensitive to avoid missing threats, which means they also generate massive amounts of false positives.
Lack of environmental context exacerbates the problem. Security tools don’t inherently understand your business processes, application behaviors, or what constitutes normal activity in your organization. When your finance team runs quarterly reports generating unusual database queries, generic detection rules flag this as potential data exfiltration. Without context about legitimate business operations, every anomaly looks potentially malicious.
Poor alert prioritization means analysts waste time investigating low-severity events while critical threats go unnoticed. When every alert appears equally urgent—or when truly urgent alerts get buried among thousands of low-priority warnings—analysts can’t effectively allocate their limited time and attention. They end up investigating alerts in the order they arrive rather than based on actual risk to the organization.
Tool sprawl multiplies the alert problem. The average enterprise uses dozens of security products, each with its own console, alert format, and notification system. Analysts must monitor multiple dashboards, correlate events across different tools, and somehow maintain a holistic view of their security posture. This fragmentation creates gaps where threats slip through and generates duplicate alerts for the same underlying event.
Insufficient staffing turns manageable alert volumes into overwhelming floods. When you lack enough analysts to properly triage and investigate incoming alerts, backlogs grow, response times increase, and the team starts taking dangerous shortcuts. Understaffed SOCs often have analysts triaging hundreds of alerts per shift without time for proper investigation—a recipe for missed threats.
Lack of detection engineering expertise prevents organizations from improving their alert quality over time. Tuning detection rules, reducing false positives, and optimizing alert thresholds requires specialized skills many security teams lack. Without ongoing refinement, alert quality stagnates or even degrades as your environment changes.
The absence of automation for repetitive tasks forces analysts to manually perform the same investigations repeatedly. When analysts spend hours enriching alerts with threat intelligence, checking whether IP addresses are malicious, or performing other routine tasks that could be automated, they have less capacity for genuine threat analysis.
This leads to a vicious cycle: overwhelming alert volumes cause analyst burnout, which leads to turnover, which creates staffing shortages, which makes the alert problem even worse. Breaking this cycle requires addressing root causes rather than just asking analysts to work harder.
What’s a healthy alert volume?
Understanding what constitutes reasonable alert volume helps you recognize when your security operations have crossed into alert fatigue territory.
Absolute volume matters less than signal-to-noise ratio. A healthy SOC might see thousands of alerts daily, but the vast majority should be automatically filtered out or quickly dismissed after minimal review. What matters is how many alerts require substantial human investigation and how many of those turn out to be genuine threats.
Industry benchmarks provide perspective: Mid-sized organizations typically see 1,000-5,000 raw alerts daily from their security tools. However, mature security operations should filter this down to perhaps 50-200 alerts requiring human review, with only 5-20 representing actual security incidents needing response.
The false positive rate reveals alert quality. If 95%+ of alerts reaching your analysts turn out to be false positives, your detection rules need tuning. Healthy security operations achieve false positive rates below 90%, meaning at least 10% of investigated alerts represent genuine security concerns worth the analyst’s time.
Alert-to-incident conversion shows whether your detection logic is working. If you’re investigating 200 alerts daily but only finding 2-3 real incidents, that’s a 1-2% conversion rate—reasonable for well-tuned systems. If you’re investigating 500 alerts to find those same 2-3 incidents, your alert quality needs improvement.
Analyst capacity provides another benchmark. A single analyst can typically handle 20-30 quality alerts per shift if they’re investigating thoroughly. If your analysts are triaging 100+ alerts per shift, they’re not doing proper investigations—they’re just clicking through screens to clear their queue, which means they’re missing threats.
Trending over time matters most. Your alert volume should decrease as your SOC matures through better tuning, improved detection rules, and elimination of chronic false positive sources. If alert volumes keep climbing without corresponding improvements in threat detection, something’s fundamentally wrong with your approach.
MDR providers achieve dramatically better signal-to-noise ratios through advanced automation that filters out noise and prioritizes real threats. They’ve refined their detection logic across hundreds of customer environments, learning which alerts truly matter and which can be safely automated away.
If your team is spending more time clearing alert queues than investigating genuine security concerns, you’ve crossed into unhealthy territory that demands immediate attention.
How do you reduce false positives?
Reducing false positives requires a systematic approach combining detection tuning, environmental context, and ongoing optimization.
Start with alert triage data analysis. Review which alerts consume the most analyst time and have the highest false positive rates. These are your optimization priorities. You might find three misconfigured rules generate 60% of your false positives—tuning those three rules dramatically improves your overall alert quality.
Add environmental context to detection rules. Generic rules flagging “unusual database access” can be refined to exclude your finance team during month-end close, your analytics team’s scheduled reporting, or your backup systems’ legitimate data access. The more your detection logic understands normal business operations, the better it distinguishes real threats from benign activities.
Implement proper alert enrichment. Before alerts reach human analysts, automatically enrich them with threat intelligence, user context, asset criticality, and historical behavior. An alert about a user accessing a sensitive file becomes much less concerning when enrichment shows they access the file every Tuesday as part of their normal job duties.
Tune thresholds based on your environment. Many detection rules use arbitrary thresholds that don’t match your actual risk profile. If your rule flags “10+ failed login attempts” but your legitimate users often mistype passwords several times, adjust the threshold to match your reality. The goal is catching actual threats, not enforcing theoretical best practices.
Leverage machine learning for behavioral baselines. Modern security platforms can learn what’s normal for each user, system, and application in your environment. Alerts based on deviations from learned baselines tend to have much higher accuracy than generic signature-based detections.
Consolidate and correlate across tools. Instead of getting separate alerts from your EDR, SIEM, and firewall about the same underlying event, correlate these into a single high-fidelity alert. This reduces alert volume while providing richer context for investigation.
Implement a continuous improvement process. Every time an analyst investigates a false positive, document why it was false and whether the detection rule can be improved. Dedicate time each week to implementing these improvements. Alert tuning isn’t a one-time project—it’s an ongoing operational requirement.
Consider the technology platform. Leading MDR services use AI-powered platforms that continuously learn from investigations across hundreds of customers to improve alert quality. What they learn from false positives at one organization immediately improves detection accuracy for all customers.
The goal isn’t eliminating all false positives—some are inevitable in effective threat detection. The goal is achieving a sustainable signal-to-noise ratio where analysts spend most of their time investigating genuine threats rather than dismissing false alarms.
What’s the impact of alert fatigue?
Alert fatigue creates cascading consequences extending far beyond frustrated security analysts.
Missed threats become inevitable. When analysts are overwhelmed by alert volumes, they start taking shortcuts. Poor prioritization becomes the norm as they spend less time investigating each alert, make assumptions based on superficial review, and eventually become desensitized to warnings. Critical threats get classified as false positives simply because no one has capacity to investigate properly. This is exactly what attackers exploit—they know overwhelmed SOCs miss subtle indicators of compromise.
Response times increase dangerously. While industry-leading MDR providers maintain a mean time to respond of 17 minutes on critical incidents, overwhelmed internal SOCs often take hours or days to respond. Every minute of delay gives attackers more time to move laterally, exfiltrate data, or deploy ransomware. Alert fatigue directly translates to longer dwell times and more severe breach impacts.
Analyst burnout accelerates. Security analysts facing impossible alert volumes and constant pressure to “work faster” burn out quickly. They experience stress, job dissatisfaction, and eventually leave for less overwhelming positions. The cybersecurity industry already faces severe talent shortages—alert fatigue makes retention even harder.
Turnover creates vicious cycles. When experienced analysts leave, you lose their institutional knowledge about what alerts matter in your environment, which systems are prone to false positives, and how to efficiently investigate different threat types. New analysts take months to develop this expertise, during which time alert handling becomes even less efficient.
Strategic security initiatives stall. Teams drowning in alert triage have no capacity for proactive security improvements. Threat hunting, security architecture reviews, detection engineering, and other high-value activities get postponed indefinitely. Your security posture stagnates because the team is entirely consumed by reactive alert response.
Compliance obligations suffer. Many regulatory frameworks require timely investigation and response to security events. When alert backlogs grow and incidents go uninvestigated, you risk compliance violations and potential fines.
Security tool ROI diminishes. Organizations invest heavily in security technologies expecting protection. But when analysts can’t effectively use those tools due to overwhelming alert volumes, the tools deliver little value. You’re paying for detection capabilities you can’t operationalize.
Leadership confidence erodes. When executives hear the security team is experiencing notification overload and can’t keep up with alerts, they question whether the organization is actually protected. This can lead to misguided responses like buying more security tools—which often makes the problem worse by adding more alert sources.
The fundamental impact: alert fatigue transforms your security operations from a protective capability into a liability, creating exploitable gaps in your defenses.
Can AI solve alert fatigue?
Artificial intelligence and machine learning offer powerful tools for reducing alert fatigue, but they’re not magic solutions that eliminate the problem entirely.
What AI does well for alert management:
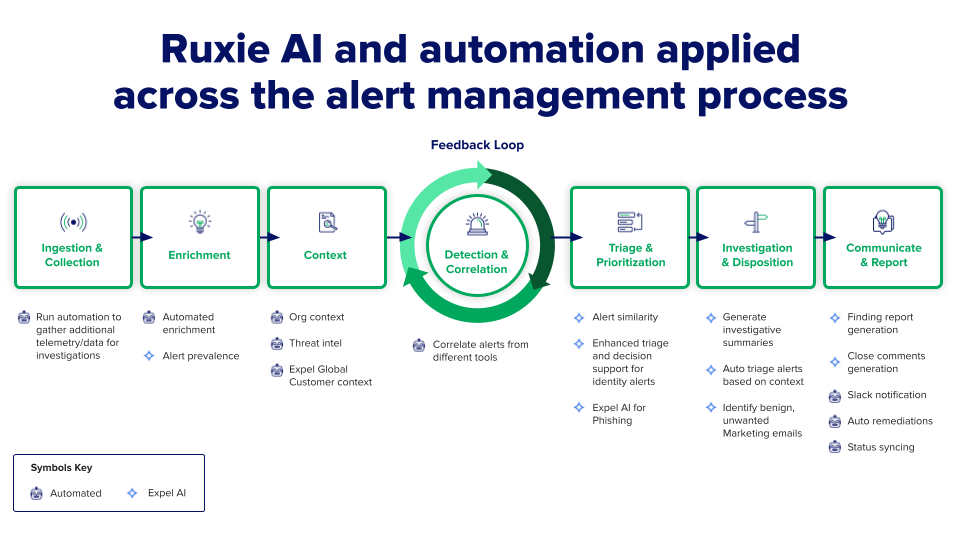
Automated alert triage uses machine learning to quickly assess incoming alerts and filter out obvious false positives. AI can automatically enrich alerts with context, compare them against threat intelligence, check whether similar alerts were previously investigated and dismissed, and route only high-confidence threats to human analysts.
Behavioral anomaly detection leverages AI to establish baselines for normal activity across users, systems, and applications. Alerts based on deviations from these learned baselines tend to have much higher accuracy than generic rule-based detections. The AI learns what’s normal for your environment specifically.
Alert correlation uses AI to identify connections between seemingly unrelated events. What appears as five separate low-priority alerts might actually represent a single coordinated attack campaign. AI can spot these patterns faster and more accurately than human analysts reviewing alerts in isolation.
Intelligent prioritization applies machine learning to rank alerts based on actual risk to your organization. AI considers factors like asset criticality, user privilege level, threat intelligence, and historical incident data to surface the alerts that truly matter.
Automated investigation handles routine enrichment tasks that previously consumed analyst time. AI can automatically check IP reputation, query threat intelligence databases, examine file hashes, review authentication logs, and gather other contextual information before the alert reaches a human analyst.
What AI can’t replace:
Human expertise remains essential for complex investigations where AI’s lack of context about your specific business processes falls short, as well as creative problem-solving for novel attack techniques and judgment calls about appropriate response actions. The most effective approach combines AI automation with human analyst expertise—letting AI handle routine tasks while humans focus on complex threats requiring intuition and experience.
Implementation challenges with AI:
AI and machine learning systems require quality data, proper configuration, and ongoing tuning to work effectively. Poorly implemented AI can create new problems—automatically dismissing genuine threats or creating false confidence leads teams to ignore alerts the AI should have caught.
The MDR advantage: Leading MDR providers have invested heavily in AI and automation platforms, refined through thousands of customer environments and millions of alerts. They’ve already solved many of the implementation challenges organizations face when trying to build their own AI-driven alert management. Their platforms learn continuously from investigations across their entire customer base, improving detection accuracy faster than any single organization could achieve independently.
AI is a powerful tool for reducing alert fatigue, but it works best when combined with human expertise, proper implementation, and continuous improvement—exactly what mature MDR services provide.
Addressing alert fatigue in your organization
Alert fatigue isn’t inevitable—it’s a solvable problem requiring the right combination of technology, expertise, and operational practices.
If your security team is drowning in alerts, start by analyzing which detection rules generate the most false positives and tune those first. Implement automated enrichment to add context before alerts reach analysts. Consider whether your team has the expertise and capacity to continuously improve detection quality—or whether partnering with an MDR provider would deliver better outcomes.
The goal is sustainable security operations where analysts spend their time investigating genuine threats rather than dismissing false alarms. Achieving this balance protects your organization while preventing the analyst burnout that makes alert fatigue a self-perpetuating problem.